Az előző jegyzetekben a numerikus és kategorikus adatokkal kapcsolatos hipotézisek tesztelésének eljárásait ismertettük: , több , valamint , amely lehetővé teszi egy vagy a tanulmányozását. Ebben a jegyzetben olyan hipotézisek tesztelésének módszereit fogjuk megvizsgálni, amelyek az általános sokaságban lévő jellemzők arányai közötti különbségekre vonatkoznak, több független minta alapján.
Az alkalmazott módszerek illusztrálására egy olyan forgatókönyvet használnak, amely felméri a T. C. Resort Properties tulajdonában lévő szállodák vendégeinek elégedettségi fokát. Képzelje el, hogy Ön egy olyan cég vezetője, amely öt szállodával rendelkezik két üdülőszigeten. Ha a vendégek elégedettek a szolgáltatással, valószínűleg jövőre is visszatérnek, és ajánlják szállodáját barátaiknak. A szolgáltatás minőségének értékeléséhez a vendégeket kérdőív kitöltésével kérik, és jelezzék, hogy elégedettek-e a vendéglátással. Elemeznie kell a felmérés adatait, meg kell határoznia a vendégek elégedettségének általános fokát, meg kell becsülnie annak valószínűségét, hogy jövőre ismét vendégei fognak jönni, és meg kell határoznia egyes ügyfelek esetleges elégedetlenségének okait. Például az egyik szigeten a cég a Beachcomber és a Windsurfer szállodák tulajdonosa. Ezekben a szállodákban ugyanaz a szolgáltatás? Ha nem, hogyan lehet ezeket az információkat felhasználni a vállalat minőségének javítására? Sőt, ha néhány vendég azt mondta, hogy többé nem jön el Önhöz, milyen indokokat adnak meg gyakrabban, mint mások? Lehet-e vitatkozni azzal, hogy ezek az okok csak egy adott szállodára vonatkoznak, és nem az egész vállalatra?
Itt a következő jelölést használjuk: x 1 - az első csoportban elért sikerek száma, x 2 - a sikerek száma a második csoportban, n 1 – x 1 - a meghibásodások száma az első csoportban, n 2 – x 2 - a meghibásodások száma a második csoportban, X=x 1 + x 2 - a sikerek teljes száma, n – x = (n 1 – x 1 ) + (n 2 – x 2 ) a hibák teljes száma, n 1 - az első minta térfogata, n 2 - a második minta térfogata, n = n 1 + n 2 a minták teljes térfogata. A bemutatott táblázat két sorból és két oszlopból áll, ezért nevezik 2x2 faktoros táblának. Az egyes sorok és oszlopok metszéspontjából képzett cellák a sikeresek vagy kudarcok számát tartalmazzák.
Szemléltessük a jellemzőkontingencia tábla alkalmazását a fent leírt példakénti forgatókönyv segítségével. Tegyük fel, hogy a kérdés: "Visszajössz jövőre?" A Beachcomber hotel 227 vendégéből 163, a Windsurfer hotel 262 vendégéből 154 válaszolt igennel. Van-e statisztikailag szignifikáns különbség a szállodai vendégelégedettség között (ami annak a valószínűsége, hogy a vendégek jövőre visszatérnek), ha a szignifikancia szint 0,05?

Rizs. 2. 2x2 faktortábla az ügyfélszolgálat minőségének értékeléséhez
Az első sor az egyes szállodák azon vendégeinek számát jelzi, akik bejelentették, hogy jövőre visszatérnek (siker); a második sorban - azon vendégek száma, akik elégedetlenséget (kudarcot) fejeztek ki. Az Összesen oszlop cellái a szállodába jövőre visszatérni tervező vendégek teljes számát, valamint a szolgáltatással elégedetlen vendégek számát tartalmazzák. Az "Összesen" sorban található cellák az egyes szállodák megkérdezett vendégeinek teljes számát tartalmazzák. A visszatérést tervező vendégek arányát úgy számítjuk ki, hogy a visszatérést bejelentő vendégek számát elosztjuk az adott szállodában megkérdezett vendégek teljes számával. Ezután a χ 2 -kritériumot alkalmazzuk a számított részesedések összehasonlítására.
A null- és alternatív hipotézisek tesztelése H 0: p 1 \u003d p 2; H 1: p 1 ≠ p 2 teszt χ 2 -statisztikát használunk.
Khi-négyzet teszt két arány összehasonlítására. A teszt χ 2 -statisztikája egyenlő a megfigyelt és a várt sikerek száma közötti különbség négyzetes összegével, osztva a táblázat egyes celláiban a várható sikerek számával:

Ahol f 0- a sikeresek vagy kudarcok megfigyelt száma a kontingenciatábla egy adott cellájában, fe
A teszt χ 2 -statisztikáját egy szabadságfokú χ 2 -eloszlással közelítjük.
Vagy a jelek kontingenciatáblázatának minden cellájában meghibásodások esetén meg kell érteni a jelentésüket. Ha a nullhipotézis igaz, pl. a sikerességi arány a két populációban egyenlő, a két csoportra számított mintaarányok csak véletlenszerű okokból térhetnek el egymástól, és mindkét arány becslés közös paraméter népesség R. Ebben a helyzetben az a statisztika, amely mindkét részesedést a paraméter egy általános (átlagos) becslésében egyesíti R , az összesített csoportok teljes sikerarányát jelenti (azaz egyenlő a sikerek teljes számával osztva a teljes mintamérettel). Az ő kiegészítése, 1 – , a teljes meghibásodási arányt jelenti az összevont csoportokban. A jelölést használva, amelynek jelentését az ábra táblázata írja le. 1. levezetheti a (2) képletet a paraméter kiszámításához :

Ahol - a jellemző átlagos részesedése.
A sikerek várható számának kiszámításához fe(azaz a jellemző-kontingencia tábla első sorának tartalma), a minta méretét meg kell szorozni a paraméterrel . A meghibásodások várható számának kiszámításához fe(azaz a jellemzőkontingencia tábla második sorának tartalma), szükséges a minta méretét megszorozni a paraméterrel 1 – .
Az (1) képlettel számított tesztstatisztikát egy szabadságfokú χ 2 -eloszlással közelítjük. Adott α szignifikanciaszint esetén a nullhipotézist elvetjük, ha a számított χ 2 -statisztika nagyobb, mint χ U 2, a χ 2 -eloszlás felső kritikus értéke egy szabadságfokkal. Tehát a döntési szabály így néz ki: a hipotézis H 0 elvetjük, ha χ 2 > χ U 2, ellenkező esetben a hipotézis H 0 nem tér el (3. ábra).

Rizs. 3. Kritikus terület χ 2 -kritériumok a részesedések összehasonlításához α szignifikancia szinten
Ha a nullhipotézis igaz, akkor a számított χ 2 -statisztika közel nulla, mivel a megfigyelések közötti különbség négyzete f 0 és várható fe az egyes cellákban lévő értékek nagyon kicsik. Másrészt, ha a nullhipotézis H 0 hamis és szignifikáns különbség van a populációk sikerességi arányai között, a számított χ 2 -statisztikának nagynak kell lennie. Ennek oka az egyes cellákban megfigyelt és várt sikerek vagy kudarcok száma közötti különbség, amely négyzetre emeléskor növekszik. Előfordulhat azonban, hogy a várt és megfigyelt értékek közötti különbségek hozzájárulása a teljes χ 2 -statisztikához nem azonos. Ugyanaz a tényleges különbség között f 0És fe nagyobb hatással lehet a χ 2 -statisztikára, ha a cella kis számú megfigyelés eredményét tartalmazza, mint a nagyobb számú megfigyelésnek megfelelő különbség.
A két rész egyenlőségének hipotézisének tesztelésére szolgáló χ 2 teszt szemléltetéséhez térjünk vissza a korábban ismertetett forgatókönyvhöz, melynek eredményeit az 1. ábra mutatja. 2. A nullhipotézis (H 0: p 1 = p 2) azt állítja, hogy két szálloda szolgáltatási minőségét összehasonlítva közel azonos a jövőre visszatérni tervező vendégek aránya. A paraméter értékeléséhez R, amely a szállodába visszatérni tervező vendégek arányát jelenti, ha a nullhipotézis igaz, akkor az értéket használjuk , amelyet a képlet számít ki

A szolgáltatással elégedetlen vendégek aránya = 1 - 0,6483 = 0,3517. Ezt a két arányt megszorozva a Beachcomber szállodában megkérdezett vendégek számával, megkapjuk a következő szezonban visszatérni tervező vendégek várható számát, valamint azoknak a nyaralóknak a számát, akik már nem szállnak meg ebben a szállodában. Hasonló módon számítják ki a Windsurfer hotel vendégeinek várható arányát:
Igen – Beachcomber:
= 0,6483, n 1
= 227, ezért fe = 147,16.
Igen - Windsurfer:
= 0,6483, n 2
= 262, ezért fe = 169,84.
Nem – Beachcomber: 1 –
= 0,3517, n 1
= 227, ezért fe = 79,84.
Nem - Szörfös: 1 -
= 0,3517, n 2
= 262, ezért fe = 92,16.
A számításokat az ábrán mutatjuk be. 4.

Rizs. 4. χ 2 -statisztikák szállodákra vonatkozóan: (a) kezdeti adatok; (b) 2x2 faktor táblázat a megfigyelt ( f 0 ) és várható ( fe) a szolgáltatással elégedett és elégedetlen vendégek száma; c) χ 2 statisztika számítása a szolgáltatással elégedett vendégek arányának összehasonlításakor; d) a χ 2 teszt statisztika kritikus értékének kiszámítása
A teszt χ 2 statisztikájának kritikus értékének kiszámításához használjuk Excel funkció=XI2.INV(). Ha az α szignifikanciaszint = 0,05 (a HI2.OBR függvénybe behelyettesített valószínűség 1 – α), és a 2×2 faktoriális táblázat χ 2 eloszlása egy szabadságfokú, akkor a χ 2 statisztika kritikus értéke 3.841. Mivel a χ 2 -statisztika számított értéke, amely 9,053 (4c. ábra), meghaladja a 3,841-et, a nullhipotézist elvetjük (5. ábra).

Rizs. 5. A teszt χ 2 -statisztika kritikus értékének meghatározása egy szabadságfokkal α = 0,05 szignifikancia szinten
Valószínűség R hogy a nullhipotézis igaz, ha a χ 2 -statisztika 9,053 (és egy szabadságfok), az Excelben a =1 - CHI2.DIST(9,053;1;TRUE) = 0,0026 függvény segítségével számítjuk ki. R-a 0,0026-os érték annak a valószínűsége, hogy a Beachcomber és a Windsurfer szállodákban a szolgáltatással elégedett vendégek mintaaránya közötti különbség egyenlő vagy nagyobb, mint 0,718 - 0,588 = 0,13, ha a részesedésük mindkét populációban ugyanaz . Jó okunk van tehát azt állítani, hogy statisztikailag szignifikáns különbség van a két szálloda vendégellátásában. A kutatások azt mutatják, hogy azoknak a vendégeknek a száma, akik elégedettek a Beachcomber szolgáltatásaival, nagyobb, mint azoknak a száma, akik ismét a Windsurferben szeretnének megszállni.
A faktortáblázatra vonatkozó feltételezések ellenőrzése 2×2. Ahhoz, hogy a 2x2 táblázatban megadott adatok alapján pontos eredményeket kapjunk, szükséges, hogy a sikerek vagy kudarcok száma meghaladja az 5-öt. Ha ez a feltétel nem teljesül, a pontos Fisher-kritérium.
Ha összehasonlítjuk a két szálloda szolgáltatási minőségével elégedett ügyfelek százalékos arányát, a Z és a χ 2 kritériumok azonos eredményre vezetnek. Ez a létezéssel magyarázható szoros kapcsolat standardizált normális eloszlás és egy szabadságfokú χ 2 -eloszlás között. Ebben az esetben a χ 2 -statisztika mindig a Z-statisztika négyzete. Például a vendégek elégedettségének felmérésekor azt tapasztaltuk Z-statisztika +3,01, χ 2 -statisztika pedig 9,05. A kerekítési hibákat figyelmen kívül hagyva könnyen ellenőrizhető, hogy a második érték az első négyzete (azaz 3,01 2 = 9,05). Ezenkívül mindkét statisztika kritikus értékét α = 0,05 szignifikanciaszinten összehasonlítva megállapítható, hogy a χ 1 2 3,841-gyel egyenlő értéke a Z-statisztika felső kritikus értékének négyzete, egyenlő +1,96-tal (azaz χ 1 2 = Z 2). Ráadásul, R- mindkét kritérium értéke megegyezik.
Így a null- és alternatív hipotézisek tesztelésekor vitatható H 0: p 1 \u003d p 2; H 1: p 1 ≠ p 2 a Z és χ 2 kritériumok egyenértékűek. Ha azonban nemcsak az eltérések kimutatására van szükség, hanem annak megállapítására is, hogy melyik arány nagyobb (p 1 > p 2), kellene alkalmazzon Z-próbát egy szabványos normális eloszlás végével határolt kritikus régióval. Az alábbiakban leírjuk a χ 2 teszt alkalmazását egy jellemző arányainak összehasonlítására több csoportban. Megjegyzendő, hogy a Z-teszt ebben a helyzetben nem alkalmazható.
A χ 2 -kritérium alkalmazása több rész egyenlőségének hipotézisének tesztelésére
A khi-négyzet teszt kiterjeszthető egy általánosabb esetre, és felhasználható annak a hipotézisnek a tesztelésére, hogy egy tulajdonság több része egyenlő. Jelöljük betűvel az elemzett független populációk számát Val vel. Most a jellemző kontingencia táblázat két sorból és Val vel oszlopok. A null- és alternatív hipotézisek tesztelése H 0: p 1 \u003d p 2 = … = 2. o, H 1: Nem mind Rj egyenlők egymással (j = 1, 2, …, c), teszt χ 2 -statisztikát használunk:
Ahol f 0- a sikerek vagy kudarcok megfigyelt száma a faktortábla egy adott cellájában 2* Val vel, fe- a sikerek vagy kudarcok elméleti vagy várható száma a kontingenciatábla egy adott cellájában, feltéve, hogy a nullhipotézis igaz.
A kontingenciatábla egyes celláiban várható sikerek vagy kudarcok számának kiszámításához a következőket kell szem előtt tartania. Ha a nullhipotézis igaz, és a sikerességi arányok minden populációban egyenlőek, akkor a megfelelő mintarészesedés csak véletlenszerű okokból térhet el egymástól, mivel minden részesedés a jellemző részesedésének becslése. R az általános lakosságban. Ebben a helyzetben egy olyan statisztika, amely az összes részesedést egyetlen általános (vagy átlagos) paraméterbecslésben egyesíti R, több információt tartalmaz, mint bármelyik külön-külön. Ez a statisztika, amelyet a szimbólum jelöl , a siker teljes (vagy átlagos) arányát jelenti az egyesített mintában.
Az átlagos részesedés kiszámítása:

A sikerek várható számának kiszámításához fe a jellemzőkontingencia táblázat első sorában minden minta térfogatát meg kell szorozni a paraméterrel. A meghibásodások várható számának kiszámításához fe a jellemző kontingencia táblázat második sorában minden minta térfogatát meg kell szorozni a paraméterrel 1 – . Az (1) képlettel számított tesztstatisztikát a χ 2 -eloszlással közelítjük. Ennek az eloszlásnak a szabadságfokainak számát a mennyiség adja meg (r - 1)(c – 1) , Ahol r- a faktortáblázat sorainak száma, Val vel- a táblázat oszlopainak száma. Tényezőtáblázathoz 2*s a szabadsági fokok száma az (2 - 1) (s - 1) = s - 1. Adott α szignifikanciaszint esetén a nullhipotézist elvetjük, ha a számított χ 2 -statisztika nagyobb, mint a χ 2 -eloszlásban rejlő χ U 2 felső kritikus érték. s - 1 szabadsági fokokat. Tehát a döntési szabály így néz ki: a hipotézis H 0 elvetjük, ha χ 2 > χ U 2 (6. ábra), ellenkező esetben a hipotézist elvetjük.

Rizs. 6. Kritikus terület χ 2 -kritérium az α szignifikanciaszintű arányhoz való viszonyításhoz
A 2*c faktortáblázatra vonatkozó feltételezések ellenőrzése. Pontos eredmények elérése a faktortáblázatban megadott adatok alapján 2* Val vel, szükséges, hogy a sikerek vagy kudarcok száma elég nagy legyen. Egyes statisztikusok úgy vélik, hogy a kritérium pontos eredményt ad, ha a várható gyakoriság nagyobb, mint 0,5. A konzervatívabb kutatók megkövetelik, hogy a kontingencia táblázat celláinak legfeljebb 20%-a tartalmazzon 5-nél kisebb várható értékeket, és egyetlen cella sem tartalmazhatja az egynél kisebb várható értéket. Ez utóbbi feltétel ésszerű kompromisszumnak tűnik e szélsőségek között. Ennek a feltételnek a teljesítéséhez a kis várható értékeket tartalmazó kategóriákat egybe kell vonni. Ezt követően a kritérium pontosabbá válik. Ha valamilyen okból nem lehetséges több kategória összekapcsolása, alternatív eljárásokat kell alkalmazni.
Az egyenlő arányok hipotézisének több csoportban történő tesztelésére szolgáló χ 2 teszt szemléltetéséhez térjünk vissza a fejezet elején leírt forgatókönyvhöz. Vegyünk egy hasonló felmérést, amelyben három T.C. Resort Resources szálloda vendégei vettek részt (7a. ábra).

Rizs. 7. 2×3 faktortáblázat a szolgáltatással elégedett és elégedetlen vendégek számának összehasonlítására: (a) a megfigyelt sikerek vagy kudarcok száma - f 0; (b) a sikerek vagy kudarcok várható száma, fe; (c) χ 2 -statisztika számítása a szolgáltatással elégedett vendégek arányának összehasonlításakor
A nullhipotézis szerint a jövőre visszatérni tervező ügyfelek aránya szinte minden szállodában azonos. A paraméter értékeléséhez R, amely a szállodába visszatérni szándékozó vendégek aránya, az értéket használjuk fel R = X /n= 513 / 700 = 0,733. A szolgáltatással elégedetlen vendégek aránya 1 - 0,733 = 0,267. Három részesedést megszorozva az egyes szállodákban megkérdezett vendégek számával, megkapjuk a következő szezonban visszatérni tervező vendégek várható számát, valamint azon ügyfelek számát, akik már nem fognak megszállni ebben a szállodában (7b. ábra).
A null- és alternatív hipotézisek tesztelésére a χ 2 teszt -statisztikát használjuk, amelyet az (1) képlet szerint a várt és megfigyelt értékekből számítunk ki (7c. ábra).
A teszt χ 2 -statisztika kritikus értékét az =XI2.OBR() képlet határozza meg. Mivel három szálloda vesz részt a felmérésben, a χ 2 -statisztika (2 – 1)(3 – 1) = 2 szabadságfok. α = 0,05 szignifikanciaszint mellett a χ 2 statisztika kritikus értéke 5,991 (7d. ábra). Mivel a számított χ 2 -statisztika, amely 40,236, meghaladja a kritikus értéket, a nullhipotézist elvetjük (8. ábra). Másrészt a valószínűség R hogy a nullhipotézis igaz a χ 2 -statisztikára, amely egyenlő 40,236-tal (és két szabadságfokkal), az Excelben az =1-XI2.DIST() = 0,000 függvény segítségével számítjuk ki (7d. ábra). R-érték egyenlő 0,000 és kisebb, mint a szignifikancia szint α = 0,05. Ezért a nullhipotézist elvetik.

Rizs. 8. ábra: A három rész egyenlősége hipotézise elfogadásának és elutasításának területei 0,05 szignifikanciaszinten és két szabadsági fokon
A nullhipotézis elvetése a faktortáblázatban feltüntetett arányok összehasonlításakor 2* Val vel, csak annyit tudunk megállapítani, hogy a három szállodában nem egyezik a szolgáltatással elégedett vendégek aránya. Ahhoz, hogy megtudjuk, mely részvények különböznek a többitől, más módszereket kell alkalmazni, például a Marasquilo eljárást.
Marasquilo eljárás lehetővé teszi az összes csoport páros összehasonlítását. Az eljárás első szakaszában a p s j – p s j ’ különbségeket számítjuk ki (ahol j ≠ j’ ) között s(ek – 1)/2 részvénypárok. A megfelelő kritikus tartományokat a következő képlettel számítjuk ki:

α általános szignifikanciaszintjén az érték egy olyan khi-négyzet eloszlás felső kritikus értékének négyzetgyöke s - 1 szabadsági fokokat. Minden egyes mintarészpárhoz külön kritikus tartományt kell kiszámítani. Az utolsó szakaszban mindegyik s(ek – 1)/2 egy pár ütemet összehasonlítunk a megfelelő kritikus tartománnyal. Az adott párt alkotó részesedéseket statisztikailag szignifikánsan eltérőnek tekintjük, ha a mintarészesedések közötti abszolút különbség |p s j – p s j | meghaladja a kritikus tartományt.
Szemléltessük a Marasquilo eljárást három szálloda vendégeinek felmérésének példáján (9a. ábra). A khi-négyzet tesztet alkalmazva azt találtuk, hogy statisztikailag szignifikáns különbség van a különböző szállodák jövőre visszatérő vendégeinek aránya között. Mivel a felmérésben három szállóvendég vesz részt, 3(3 - 1)/2 = 3 páronkénti összehasonlítást kell végezni, és három kritikus tartományt kell kiszámítani. Először számítsunk ki három mintarészesedést (9b. ábra). 0,05 általános szignifikanciaszint mellett a χ 2 -statisztika teszt felső kritikus értékét a "khi-négyzet" eloszlásra, amelynek (c - 1) = 2 szabadsági foka van, az = XI2.OBR képlet határozza meg. (0,95; 2) = 5,991. Tehát = 2,448 (9c. ábra). Ezután kiszámítjuk három abszolút különbségpárt és a megfelelő kritikus tartományokat. Ha az abszolút különbség nagyobb, mint a kritikus tartománya, akkor a megfelelő részarányokat szignifikánsan eltérőnek tekintjük (9d. ábra).

Rizs. 9. ábra: A Marasquilo eljárás eredményei a három szálloda elégedett vendégeinek egyenlő arányára vonatkozó hipotézis tesztelésére: (a) felmérési adatok; b) mintarészvények; (c) a khi-négyzet eloszlásra vonatkozó χ 2 tesztstatisztika felső kritikus értéke; d) három pár abszolút különbség és a megfelelő kritikus tartomány
Mint látható, 0,05-ös szignifikancia szinten a Palm Royal szálloda vendégeinek elégedettségi foka (p s2 = 0,858) magasabb, mint az Arany Pálma (p s1 = 0,593) és Palm Princess vendégeinek. szállodák (p s3 = 0,738). Emellett a Palm Princess Hotel vendégeinek elégedettsége magasabb, mint a Golden Palm Hotel vendégeinek. Ezek az eredmények arra késztetik a vezetőséget, hogy elemezze a különbségek okait, és próbálja meg meghatározni, hogy az Arany Pálma vendégelégedettségi mutatója miért lényegesen alacsonyabb, mint más szállodáké.
A Levin és munkatársai: Statisztikák menedzsereknek című könyvéből származó anyagokat használjuk. - M.: Williams, 2004. - p. 708–730
A Pearson-féle khi-négyzet teszt egy nem-paraméteres módszer, amely lehetővé teszi az egyes kategóriákba tartozó minta tényleges (a vizsgálat eredményeként feltárt) kimeneteleinek száma vagy minőségi jellemzői és az elméleti szám közötti különbségek szignifikanciájának felmérését. amit a nullhipotézis igaza esetén a vizsgált csoportokban elvárhatunk. Egyszerűbben fogalmazva, a módszer lehetővé teszi két vagy több közötti különbség statisztikai szignifikanciájának értékelését relatív mutatók(frekvenciák, részvények).
1. A χ 2 kritérium kialakulásának története
A kontingenciatáblázatok elemzésére szolgáló khi-négyzet tesztet 1900-ban fejlesztette ki és javasolta egy angol matematikus, statisztikus, biológus és filozófus, a matematikai statisztika megalapítója és a biometrikus adatok egyik megalapítója. Karl Pearson(1857-1936).
2. Mire használható a Pearson-féle χ 2 kritérium?
A khi-négyzet teszt alkalmazható az elemzésben készenléti táblázatok információkat tartalmaz a kimenetelek gyakoriságáról egy kockázati tényező jelenlététől függően. Például, négymezős kontingenciatábla alábbiak szerint:
| Az Exodus az (1) | Nincs kijárat (0) | Teljes | |
| Van egy kockázati tényező (1) | A | B | A+B |
| Nincs kockázati tényező (0) | C | D | C+D |
| Teljes | A+C | B+D | A+B+C+D |
Hogyan kell kitölteni egy ilyen tartaléktáblát? Nézzünk egy kis példát.
Folyamatban van egy tanulmány a dohányzásnak az artériás hipertónia kialakulásának kockázatára gyakorolt hatásáról. Ehhez két alanycsoportot választottak ki - az elsőbe 70 fő volt, akik naponta legalább 1 doboz cigarettát szívtak el, a másodikba pedig 80 azonos korú nemdohányzót. Az első csoportban 40 embernek volt magas vérnyomása. A másodikban 32 embernél figyelték meg az artériás magas vérnyomást. Ennek megfelelően a normál vérnyomás a dohányosok csoportjában 30 fő (70-40 = 30), a nemdohányzók csoportjában pedig 48 fő (80-32 = 48) volt.
A négymezős kontingencia táblát kitöltjük a kiindulási adatokkal:
Az így kapott kontingenciatáblázatban minden sor a tantárgyak meghatározott csoportjának felel meg. Oszlopok - az artériás hipertóniában vagy normál vérnyomásban szenvedők számát mutatják.
A kutató előtt álló kihívás az: vannak-e statisztikailag szignifikáns különbségek a vérnyomásosok gyakorisága között a dohányosok és a nemdohányzók körében? Erre a kérdésre úgy válaszolhat, hogy kiszámítja a Pearson-féle khi-négyzet tesztet, és összehasonlítja a kapott értéket a kritikus értékkel.
3. A Pearson-féle khi-négyzet teszt alkalmazásának feltételei és korlátozásai
- Összehasonlítható mutatókat kell mérni névleges méretarány(például a páciens neme - férfi vagy nő) vagy in sorrendi(például az artériás magas vérnyomás mértéke, 0 és 3 közötti értékeket véve).
- Ez a módszer nem csak négymezős táblázatok elemzését teszi lehetővé, amikor a faktor és az eredmény is bináris változó, azaz csak két lehetséges értékük van (például férfi vagy nő, egy bizonyos betegség jelenléte vagy hiánya a történelemben ...). A Pearson-féle khi-négyzet teszt használható többmezős táblák elemzésekor is, amikor a faktor és (vagy) eredmény három vagy több értéket vesz fel.
- Az illesztett csoportoknak függetlennek kell lenniük, azaz a khi-négyzet tesztet nem szabad használni az előtte-utána megfigyelések összehasonlításakor. McNemar teszt(két rokon sokaság összehasonlításakor) vagy számított Q-teszt Cochran(három vagy több csoport összehasonlítása esetén).
- Négymezős táblák elemzésekor várható értékek minden cellában legalább 10-nek kell lennie. Abban az esetben, ha legalább egy cellában a várható jelenség 5 és 9 közötti értéket vesz fel, akkor a khi-négyzet tesztet kell kiszámítani Yates korrekcióval. Ha legalább egy cellában a várt jelenség 5-nél kisebb, akkor az elemzést kell használni Fisher pontos tesztje.
- Többmezős táblázatok elemzése esetén a várt megfigyelések száma a cellák több mint 20%-ában nem lehet 5-nél kisebb.
4. Hogyan számítsuk ki a Pearson-féle khi-négyzet tesztet?
A khi-négyzet teszt kiszámításához a következőket kell tennie:

Ez az algoritmus négymezős és többmezős táblákhoz egyaránt alkalmazható.
5. Hogyan értelmezzük a Pearson-féle khi-négyzet teszt értékét?
Abban az esetben, ha a χ 2 kritérium kapott értéke nagyobb, mint a kritikus, arra a következtetésre jutunk, hogy a vizsgált kockázati tényező és az eredmény között a megfelelő szignifikanciaszinten statisztikai kapcsolat van.
6. Példa a Pearson-khi-négyzet próba kiszámítására
Határozzuk meg a dohányzási tényezőnek az artériás hipertónia előfordulására gyakorolt hatásának statisztikai szignifikanciáját a fenti táblázat alapján!
- Minden cellához kiszámítjuk a várható értékeket:
- Keresse meg a Pearson-féle khi-négyzet teszt értékét:
χ 2 \u003d (40-33,6) 2 / 33,6 + (30-36,4) 2 / 36,4 + (32-38,4) 2 / 38,4 + (48-41,6) 2 / 41,6 \u003d 4,396.
- A szabadsági fokok száma f = (2-1)*(2-1) = 1. A táblázatból megtaláljuk a Pearson khi-négyzet próba kritikus értékét, amely p=0,05 szignifikanciaszinten és a szabadságfok száma 1, 3,841.
- A khi-négyzet teszt kapott értékét összehasonlítjuk a kritikus értékkel: 4,396 > 3,841, ezért az artériás hipertónia előfordulási gyakoriságának a dohányzás jelenlététől való függése statisztikailag szignifikáns. Ennek a kapcsolatnak a szignifikancia szintje p<0.05.
Vegye figyelembe az alkalmazástKISASSZONYEXCELPearson-khi-négyzet teszt egyszerű hipotézisek tesztelésére.
A kísérleti adatok beérkezése után (vagyis amikor van néhány minta) általában olyan elosztási törvényt választanak, amely a legjobban leírja valószínűségi változó ezzel bemutatva mintavétel. Annak ellenőrzését, hogy a kísérleti adatokat mennyire írja le jól a választott elméleti eloszlási törvény, a segítségével végezzük beleegyezési kritériumok. null hipotézist, általában létezik egy olyan hipotézis, hogy egy valószínűségi változó eloszlása megegyezik valamilyen elméleti törvénnyel.
Először nézzük meg az alkalmazást Pearson-féle illeszkedési teszt X 2 (khi-négyzet) egyszerű hipotézisekkel kapcsolatban (az elméleti eloszlás paramétereit ismertnek feltételezzük). Ekkor - , amikor csak az eloszlási forma van megadva, és ennek az eloszlásnak a paraméterei és az értéke statisztika X 2 ennek alapján becsülik/számítják minták.
jegyzet: Az angol nyelvű szakirodalomban a pályázati eljárás Pearson alkalmassági tesztje X 2 neve van Az illeszkedés khi-négyzet jósági tesztje.
Emlékezzünk vissza a hipotézisek tesztelésének eljárására:
- alapján mintákérték kiszámításra kerül statisztika, amely megfelel a tesztelt hipotézis típusának. Például használni t-statisztika(ha nem ismert);
- alávetve az igazságnak null hipotézist, ennek eloszlása statisztika ismert és felhasználható valószínűségek kiszámítására (például: t- statisztika Ez );
- alapján számítják ki minták jelentése statisztikaösszehasonlítva az adott érték kritikus értékével ();
- null hipotézist elutasítva, ha az érték statisztika nagyobb a kritikusnál (vagy ha ennek az értéknek a valószínűsége statisztika() Kevésbé szignifikancia szintje, ami az egyenértékű megközelítés).
Töltsük hipotézis tesztelés különböző disztribúciókhoz.
Diszkrét eset
Tegyük fel, hogy két ember kockáznak. Minden játékosnak megvan a saját kockakészlete. A játékosok felváltva dobnak egyszerre 3 kockával. Minden kört az nyer, aki egyszerre több hatost dob. Az eredményeket rögzítjük. Az egyik játékosnak 100 kör után az a gyanúja támadt, hogy ellenfele csontjai nem szimmetrikusak, mert. gyakran nyer (gyakran hatost dob). Elhatározta, hogy elemzi, mennyire valószínű, hogy ilyen számú ellenfél kimenetele lesz.
jegyzet: Mert 3 dobókockával, akkor egyszerre 0-t dobhatsz; 1; 2 vagy 3 hatos, pl. a valószínűségi változó 4 értéket vehet fel.
A valószínűségelméletből tudjuk, hogy ha a kockák szimmetrikusak, akkor a hatos kiesésének valószínűsége engedelmeskedik. Ezért 100 kör után a képlet segítségével kiszámítható a hatosok gyakorisága
=BINOM.ELOSZ.(A7;3;1/6;HAMIS)*100
A képlet feltételezi, hogy a cella A7 egy körben a megfelelő számú kiesett hatost tartalmazza.
jegyzet: A számítások a következőkben vannak megadva példafájl a Discrete lapon.
Összehasonlításképp megfigyelt(Megfigyelt) és elméleti frekvenciák(Várható) kényelmesen használható.

A megfigyelt gyakoriságok jelentős eltérésével az elméleti eloszlástól, null hipotézist egy valószínűségi változó elméleti törvény szerinti eloszlásáról, el kell utasítani. Vagyis ha az ellenfél kockái nem szimmetrikusak, akkor a megfigyelt frekvenciák „jelentősen eltérnek” a binomiális eloszlás.
A mi esetünkben első ránézésre elég közel állnak a frekvenciák, és számítások nélkül nehéz egyértelmű következtetést levonni. Alkalmazható Pearson-féle illeszkedési teszt X 2, így a szubjektív „jelentősen más” állítás helyett, ami az összehasonlítás alapján tehető hisztogramok, használjon matematikailag helyes állítást.
Használjuk azt a tényt nagy számok törvénye megfigyelt gyakoriság (Megfigyelt) növekvő hangerővel minták n az elméleti törvénynek megfelelő valószínűségre hajlik (esetünkben binomiális törvény). Esetünkben az n mintanagyság 100.
Bemutatjuk teszt statisztika, amit X 2-vel jelölünk:

ahol O l azoknak az eseményeknek a megfigyelt gyakorisága, amelyeknél a valószínűségi változó bizonyos elfogadható értékeket vett fel, E l a megfelelő elméleti gyakoriság (várható). L az értékek száma, amelyet egy valószínűségi változó felvehet (a mi esetünkben 4).
Ahogy a képletből is látszik, ez statisztika a megfigyelt frekvenciák elméletihez való közelségének mértéke, azaz. segítségével meg lehet becsülni e frekvenciák közötti "távolságokat". Ha ezeknek a "távolságoknak" az összege "túl nagy", akkor ezek a frekvenciák "lényegében eltérőek". Nyilvánvaló, hogy ha a kockánk szimmetrikus (azaz alkalmazható binomiális törvény), akkor kicsi lesz annak a valószínűsége, hogy a „távolságok” összege „túl nagy” lesz. Ennek a valószínűségnek a kiszámításához ismernünk kell az eloszlást statisztika X 2 ( statisztika X 2 véletlenszerűen számítva minták, tehát ez egy valószínűségi változó, és ezért megvan a sajátja Valószínűségi eloszlás).
Többdimenziós analógból Moivre-Laplace integrál tétel ismert, hogy n->∞ esetén az X 2 valószínűségi változónk aszimptotikusan L - 1 szabadságfokkal.
Tehát ha a számított érték statisztika X 2 (a frekvenciák közötti „távolságok” összege) nagyobb lesz egy bizonyos határértéknél, akkor lesz okunk az elutasításra. null hipotézist. Mint az ellenőrzésnél parametrikus hipotézisek, a határérték beállítása ezen keresztül történik szignifikancia szintje. Ha annak a valószínűsége, hogy az X 2 statisztika kisebb vagy egyenlő értéket vesz fel, mint a számított ( p-jelentése) kevesebb lesz szignifikancia szintje, Azt null hipotézist elutasítható.
Esetünkben a statisztikai érték 22,757. Annak a valószínűsége, hogy az X 2 statisztika 22,757-nél nagyobb vagy egyenlő értéket vesz fel, nagyon kicsi (0,000045), és a képletekkel kiszámítható
=XI2.ELTOL.PX(22,757;4-1) vagy
=XI2.TESZT(Megfigyelt; Várható)
jegyzet: A CH2.TEST() függvény kifejezetten két kategorikus változó közötti kapcsolat tesztelésére szolgál (lásd ).
A 0,000045 valószínűség lényegesen kisebb a szokásosnál szignifikancia szintje 0,05. Tehát a játékosnak minden oka megvan arra, hogy ellenfelét tisztességtelenséggel gyanúsítsa ( null hipotézist az őszinteségét megtagadják).

Alkalmazáskor X 2. kritériumügyelni kell arra, hogy a hangerőt minták n elég nagy volt, különben az eloszlás közelítése érvénytelen lenne statisztika X 2. Általában úgy gondolják, hogy ehhez elegendő, ha a megfigyelt frekvenciák (megfigyelt) nagyobbak, mint 5. Ha ez nem így van, akkor az alacsony frekvenciákat egyesítik vagy más frekvenciákhoz kapcsolják, és az összesített értékhez hozzárendeljük a teljes értéket. valószínűsége és ennek megfelelően a szabadsági fokok száma csökken X 2 -eloszlás.
Az alkalmazás minőségének javítása érdekében X 2. kritérium(), csökkenteni kell a particionálási intervallumokat (növelje az L-t, és ennek megfelelően növelje a számot szabadsági fokokat), ezt azonban megakadályozza az egyes intervallumokba eső megfigyelések számának korlátozása (d.b.>5).
folyamatos ügy
Pearson alkalmassági teszt X 2 esetén ugyanúgy alkalmazható.
Fontolja meg néhányat mintavétel, amely 200 értékből áll. Null hipotézist azt állítja minta készült .
jegyzet: Véletlenszerű változók mintafájl a lapon Folyamatos képlet segítségével generált =NORM.ST.INV(RAND()). Ezért új értékek minták minden alkalommal generálódnak, amikor a munkalap újraszámításra kerül.
Vizuálisan értékelhető, hogy a rendelkezésre álló adatsor megfelelő-e.

Amint az ábrán látható, a mintaértékek elég jól illeszkednek az egyenes mentén. Azonban, mint a hipotézis tesztelés alkalmazható Pearson-féle illeszkedési teszt X 2 .
Ehhez egy valószínűségi változó variációs tartományát 0,5 lépéssel intervallumokra osztjuk. Számítsuk ki a megfigyelt és az elméleti gyakoriságokat. A megfigyelt frekvenciákat a FREQUENCY() függvénnyel, az elméletieket pedig a NORM.ST.DIST() függvény segítségével számítjuk ki.
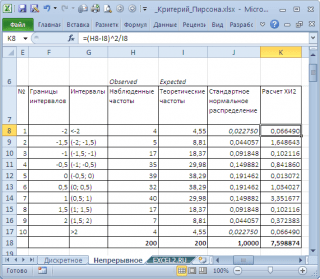
jegyzet: Ami azt illeti diszkrét eset, biztosítani kell azt minta elég nagy volt, és több mint 5 érték esett az intervallumba.
Számítsa ki az X 2 statisztikát, és hasonlítsa össze egy adott kritikus értékével! szignifikancia szintje(0,05). Mert egy valószínűségi változó variációs tartományát 10 intervallumra osztottuk, ekkor a szabadsági fokok száma 9. A kritikus érték a képlettel számítható
\u003d XI2.INV.RH (0,05; 9) vagy
\u003d XI2.OBR (1-0,05; 9)
A fenti diagramon látható, hogy a statisztikai érték 8,19, ami szignifikánsan magasabb kritikai – null hipotézist nincs elutasítva.
Az alábbiakban arról van szó, hogy melyik minta valószínűtlen értéket vett fel, és alapján kritériumok Pearson beleegyezése X 2 a nullhipotézist elvetették (annak ellenére, hogy a véletlen értékeket a képlet segítségével generálták =NORM.ST.INV(RAND()) gondoskodás mintavétel tól től szabványos normál eloszlás).

Null hipotézist elutasítva, bár vizuálisan az adatok meglehetősen közel állnak az egyeneshez.
Példaként vegyük azt is mintavétel U(-3; 3)-ból. Ebben az esetben már a grafikonon is jól látszik, hogy null hipotézist el kell utasítani.

Kritérium Pearson beleegyezése X 2 ezt is megerősíti null hipotézist el kell utasítani.
Legyen H 0, hogy F(x) = F 0 (x); alternatív hipotézis Н 1: F(x) ¹ F 0 (x). A Pearson-féle illeszkedési tesztben a c 2 valószínűségi változót vesszük statisztikának, melynek tapasztalati értékét a képlet határozza meg.
ahol k azoknak az intervallumoknak a száma, amelyekre a vizsgált SW X értéke fel van osztva; m i – az i intervallum gyakorisága; p i annak a valószínűsége, hogy az SS X az i-edik intervallumba esik, az elméleti eloszlási törvényre számolva.
Mivel n ® ¥, SW hajlamos c 2 s eloszlásra l= k – r – 1 szabadságfok, ahol k az intervallumok száma, r a kísérleti adatokból számított elméleti eloszlási paraméterek száma.
Az a követelmény, hogy n ® ¥ elengedhetetlen. A gyakorlatban az n ³ 50 térfogatot és a megfigyelések számát az egyes m i intervallumokban legalább 5-nek tekintjük. Ha bármely m i intervallumban< 5, то имеет смысл объединить соседние интервалы.
Leírjuk a c 2 kritérium alkalmazásának algoritmusát.
1. Az érték megtalálható
2. A kiválasztott a szinthez a VI. függelék szerint keresse meg a , ahol értéket l= k - r - 1.
3. Ha £, akkor a H 0 hipotézis elfogadott, azaz. feltételezhetjük, hogy az eloszlások elméleti és empirikus törvényei egybeesnek; Ha
> , akkor a H 0 hipotézist elvetjük.
29.2. PÉLDA. A lenmag vetésekor fontos mutató a vetőmag kihelyezésének mélysége. 100 mérést végeztünk a vetés értékelésére. A mérési eredményeket a 29.3. táblázat tartalmazza.
29.3. táblázat.
A c 2 kritérium segítségével tesztelje a H 0 hipotézist az SS X normális eloszlásáról - a vetőmag elhelyezési mélysége a szignifikancia szinten a = 0,01.
Megoldás. Keressük meg és S B-t a mintaadatok szerint
Mivel a szélső intervallumokban m i értéke< 5, объединим их.
29.4. táblázat.
1. Határozzuk meg az SV X eltalálásának p i valószínűségét az i intervallumban a képlet szerint
ahol a mellékletek II. táblázata segítségével találjuk meg az értékeket.
Vizsga: .
Számítsuk ki az értéket:
2. l\u003d k - r - 1 \u003d 5 - 2 - 1 \u003d 2. A II. táblázat szerint \u003d 9,21-et találunk.
3. Mert< , то гипотезу Н 0 о нормальном распределении СВ Х отвергать нет оснований.
30. § A minták homogenitására vonatkozó hipotézisek tesztelése (nem paraméteres kritériumok).
Legyen két független minta olyan sokaságból, amelyek eloszlási törvényei ismeretlenek. Ellenőrzött H 0 hipotézis: F 1 (x) = F 2 (x), ahol F 1 (x) és F 2 (x) ismeretlen eloszlásfüggvények. Alternatív H 1 hipotézis: F 1 (x) ¹ F 2 (x).
Kolmogorov-Smirnov kritérium. Ezt a kritériumot akkor kell alkalmazni, ha feltételezhető, hogy az F 1 (x) és F 2 (x) függvények folytonosak.
Az érték
ahol n 1 , n 2 az első és a második minta térfogata, F 1,E (x), F 2,E (x) az első és második minta empirikus eloszlásfüggvényei.
Ha a H 0 hipotézis kellően nagy mintákra érvényes (n 1 ³ 50, n 2 ³ 50), az eloszlás konvergál a Kolmogorov-eloszláshoz (mellékletek VII. táblázata). Kis minták esetén speciális táblázatokat használnak a Dcr megkeresésére.
A H 0 hipotézist a következőképpen teszteljük. Ha
> D cr, akkor a hipotézist elvetjük, ellenkező esetben elfogadjuk.
30.1. PÉLDA. Egy bizonyos gyógyszer malacok növekedésére gyakorolt hatásának vizsgálatára kísérletet végeztünk, melynek eredményeit a 30.1. táblázat mutatja be.
30.1. táblázat.
Ugyanakkor a kontrollcsoport malacait gyógyszer használata nélkül etették (30.2. táblázat).
30.2. táblázat.
Az a = 0,05 szignifikancia szinten szükséges ellenőrizni azt a H 0 hipotézist, hogy mindkét mintát ugyanaz az eloszlásfüggvény írja le, azaz. a gyógyszernek nincs jelentős hatása a malacok növekedésére.
Megoldás. A számítási adatokat ennek figyelembevételével írjuk be a táblázatba
n 1 \u003d 100, n 2 = 200.
30.3. táblázat.
A mellékletek VII. táblázatát felhasználva megállapítjuk
D cr = D 1 - a = D 0,95 "K 0,95 \u003d 1,36.
Mivel D kr< , то гипотезу Н 0 следует принять, т.е. препарат не оказывает существенного влияния на рост поросят.
Ha a minták kicsik, kényelmesen használható Wilcoxon-Whitney teszt.
Fogalmazzunk meg egy szabályt az alkalmazására (n 1 £ 25, n 2 £ 25). A H 0: F 1 (x) = F 2 (x) hipotézis teszteléséhez egy alternatív H 1: F 1 (x) ¹ F 2 (x) hipotézissel a következő:
1. Két mintát egyesítsen egybe, és rendezze az opciókat növekvő sorrendbe, számítsa ki W-t - egy kisebb minta opciójának számainak összegét.
2. Keresse meg a Függelék VIII. táblázatából w alsó.cr = w( , n 1 , n 2) és w felső.cr =
\u003d (n 1 + n 2 + 1) n 1 - w alsó kr.
Ha w n.cr< W < w в.кр, то нет оснований отвергнуть гипотезу, в противоположном случае гипотеза Н 0 отвергается.
Megjegyzés 30.1. Ha van köztük egyezési lehetőség, akkor mindegyikhez az általános sorozatban szereplő illesztési opciók sorszámának számtani középértékével megegyező rangokat rendelünk, amelyek helyettesítik az illesztési lehetőségek számait.
Megjegyzés 30.2. A Wilcoxon-Whitney teszt nagy minták esetén is használható. Ebben az esetben a w n.cr és w v.cr számítása megváltozik (lásd).
30.2. PÉLDA. A bérek becsléséhez (c.u.-ban) két n 1 = 8 és n 2 = 9 mintát gyűjtöttek két vállalkozásnál:
I-edik vállalkozás 330, 390, 400, 410, 420, 450, 460, 470
II. vállalkozás 340, 400, 410, 420, 430, 440, 460, 480, 490
A Wilcoxon-Whitney teszt segítségével tesztelje a H 0 nullhipotézist, amely két vállalatnál azonos fizetésről szól, szemben a H 1: a fizetés eltérő hipotézissel (a = 0,05).
Megoldás. Alkossunk egy általános variációs sorozatot
330 ; 340; 390 ; 400 ; 400; 410 ; 410; 420 ; 420; 430; 440; 450 ; 460 ; 460; 470 ; 480; 490
1 2 34,5 4,5 6,5 6,5 8,5 8,5 10 11 1213,5 13,5 15 16 17
A fenti Wilcoxon-Whitney teszt alkalmazásához az első minta legyen a legkisebb méretű n 1 = 8.
Határozzuk meg W értékét. Ehhez húzzuk alá a kisebb minta változatának sorszámait, és keressük meg azok összegét:
W = 1 + 3 + 4,5 + 6,5 + 8,5 + 12 + 13,5 + 15 = 64.
Keresse meg a w alacsonyabb értéket.cr = w(0,025; 8; 9) = 51.
Keresse meg a w top.cr = (n 1 + n 2 + 1) n 1 - w n.cr = (8 + 9 + 1) × 8 - 51 = 93 értéket.
Mivel a reláció w n.cr< W < w в.кр (51 < 64 < 93), то нет оснований отвергнуть гипотезу Н 0 , т.е. оплата труда на I-м и II-м предприятиях различается незначительно.
ODA. Az empirikus frekvenciák valójában megfigyelt frekvenciák.
AZ ÁLTALÁNOS LÉPESSÉG FELTÉTELÉRE VONATKOZÓ HIPOTÉZIS ELLENŐRZÉSE. PEARSON KRITÉRIUMA
Mint korábban említettük, az eloszlás típusára vonatkozó feltevés elméleti premisszák alapján tehető fel. Azonban bármennyire is jól választjuk meg az elméleti eloszlási törvényt, elkerülhetetlenek az eltérések az empirikus és az elméleti eloszlás között. Természetesen felmerül a kérdés: vajon ezek az eltérések csak korlátozott számú megfigyeléssel összefüggő véletlenszerű körülményekből fakadnak, vagy jelentősek, és az elméleti eloszlási törvény sikertelenségével kapcsolatosak. A kérdés megválaszolására szolgál az egyetértés kritériuma, i.e.
ODA. Konkordancia kritérium az ismeretlen eloszlás javasolt törvényének hipotézisének tesztelésének kritériuma.
Minden egyes kritériumra, pl. megfelelő eloszlás, általában táblázatokat állítanak össze, amelyek szerint találnak k kr (lásd a mellékleteket). A kritikus pont megtalálása után a mintaadatokból kiszámítjuk a kritérium megfigyelt értékét NAK NEK obs. Ha NAK NEK obs > k kr, akkor a nullhipotézist elvetjük, ha fordítva, akkor elfogadjuk.
Ismertesse a Pearson-kritérium alkalmazását az általános sokaság normális eloszlására vonatkozó hipotézis tesztelésére. A Pearson-kritérium arra a kérdésre ad választ, hogy vajon véletlen-e az empirikus és elméleti frekvenciák közötti eltérés?
A Pearson-kritérium, mint bármely más ismérv, nem bizonyítja a hipotézis érvényességét, hanem csak azt állapítja meg, a szignifikancia elfogadott szintjén, hogy egyezik-e vagy nem egyezik-e a megfigyelési adatokkal.
Tehát kapjunk empirikus eloszlást egy n méretű mintából. A szignifikancia szinten a nullhipotézis tesztelése szükséges: a sokaság normális eloszlású.
A nullhipotézis tesztelésének kritériumaként egy c 2 = valószínűségi változót veszünk, ahol az empirikus gyakoriságok vannak; - elméleti frekvenciák.
Ennek az SW-nek c 2 - eloszlása van k - szabadságfokkal. A szabadsági fokok számát a k=m –r -1 egyenlet határozza meg, m a parciális mintavételi intervallumok száma; r az eloszlási paraméterek száma. Normál eloszlás esetén r=2 (a és s), akkor k=m –3.
A nullhipotézis adott szignifikanciaszintű teszteléséhez: a sokaság normális eloszlású, szükséges:
1. Számítsa ki a minta átlagát és a minta szórását!
2. Számítsa ki az elméleti frekvenciákat,
ahol n a minta mérete; h - lépés (két szomszédos lehetőség közötti különbség); ; függvényértékek nézd meg az alkalmazást.
3. Hasonlítsa össze az empirikus és elméleti gyakoriságokat Pearson-teszt segítségével! Ezért:
a) keresse meg a kritérium megfigyelt értékét;
b) a c 2 kritikus eloszlási pontok táblázata alapján az adott a szignifikanciaszint és a k szabadsági fokok száma szerint keresse meg a kritikus pontot .
Ha< - нет оснований отвергнуть нулевую гипотезу. Если >- A nullhipotézist elvetik.
Megjegyzés. Kevés frekvencia (<5) следует объединить; в этом случае и соответствующие им теоретические частоты также надо сложить. Если производилось объединение частот, то при определении числа степеней свободы следует в качестве m принять число групп выборки, оставшихся после объединения частот.