Dalam catatan sebelumnya, prosedur pengujian hipotesis tentang data numerik dan kategori telah dijelaskan: , beberapa , dan juga , yang memungkinkan Anda mempelajari satu atau . Dalam catatan ini, kami akan mempertimbangkan metode untuk menguji hipotesis tentang perbedaan antara proporsi fitur dalam populasi umum berdasarkan beberapa sampel independen.
Untuk mengilustrasikan metode yang digunakan, digunakan skenario yang menilai tingkat kepuasan tamu hotel milik T. C. Resort Properties. Bayangkan Anda adalah manajer sebuah perusahaan yang memiliki lima hotel yang berlokasi di dua pulau resor. Jika tamu puas dengan layanannya, kemungkinan besar mereka akan kembali tahun depan dan merekomendasikan hotel Anda kepada teman mereka. Untuk mengevaluasi kualitas layanan, para tamu diminta mengisi kuesioner dan menunjukkan apakah mereka puas dengan keramahtamahannya. Anda perlu menganalisis data survei, menentukan tingkat kepuasan tamu secara keseluruhan, memperkirakan kemungkinan tamu akan datang lagi tahun depan, dan juga menentukan alasan kemungkinan ketidakpuasan beberapa pelanggan. Misalnya, di salah satu pulau, perusahaan memiliki hotel Beachcomber dan Windsurfer. Apakah layanannya sama di hotel-hotel ini? Jika tidak, bagaimana informasi ini dapat digunakan untuk meningkatkan kualitas perusahaan? Selain itu, jika beberapa tamu mengatakan bahwa mereka tidak akan mendatangi Anda lagi, alasan apa yang lebih sering mereka berikan daripada yang lain? Dapatkah dikatakan bahwa alasan ini hanya berlaku untuk hotel tertentu dan tidak berlaku untuk seluruh perusahaan secara keseluruhan?
Notasi berikut digunakan di sini: X 1 - jumlah keberhasilan di grup pertama, X 2 - jumlah keberhasilan di kelompok kedua, N 1 – X 1 - jumlah kegagalan pada kelompok pertama, N 2 – X 2 - jumlah kegagalan pada kelompok kedua, X=X 1 + X 2 - jumlah total keberhasilan, N – X = (N 1 – X 1 ) + (N 2 – X 2 ) adalah jumlah total kegagalan, N 1 - volume sampel pertama, N 2 - volume sampel kedua, N = N 1 + N 2 adalah volume total sampel. Tabel yang ditampilkan memiliki dua baris dan dua kolom, oleh karena itu disebut tabel faktor 2x2. Sel-sel yang dibentuk oleh persimpangan setiap baris dan kolom berisi jumlah keberhasilan atau kegagalan.
Mari kita ilustrasikan penerapan tabel kontingensi fitur menggunakan skenario yang dijelaskan di atas sebagai contoh. Misalkan pertanyaan "Apakah Anda akan kembali tahun depan?" 163 dari 227 tamu di hotel Beachcomber menjawab ya, dan 154 dari 262 tamu di hotel Windsurfer. Apakah ada perbedaan yang signifikan secara statistik antara kepuasan tamu hotel (yang merupakan probabilitas tamu akan kembali tahun depan) jika tingkat signifikansinya 0,05?

Beras. 2. Tabel faktor 2x2 untuk menilai kualitas layanan pelanggan
Baris pertama menunjukkan jumlah tamu setiap hotel yang menyatakan keinginan untuk kembali tahun depan (sukses); di baris kedua - jumlah tamu yang menyatakan ketidakpuasan (kegagalan). Sel-sel di kolom Total berisi jumlah tamu yang berencana untuk kembali ke hotel tahun depan, serta jumlah tamu yang tidak puas dengan layanan tersebut. Sel yang terletak di baris "Total" berisi jumlah total tamu yang diwawancarai di setiap hotel. Proporsi tamu yang berencana untuk kembali dihitung dengan membagi jumlah tamu yang dilaporkan kembali dengan jumlah total tamu yang disurvei di hotel tersebut. Kemudian, kriteria χ 2 - diterapkan untuk membandingkan bagian yang dihitung.
Untuk menguji hipotesis nol dan alternatif H 0: p 1 \u003d p 2; H 1: p 1 ≠ p 2 kami menggunakan uji χ 2 -statistik.
Uji chi-square untuk membandingkan dua proporsi. Uji χ 2 -statistik sama dengan jumlah perbedaan kuadrat antara jumlah keberhasilan yang diamati dan yang diharapkan, dibagi dengan jumlah keberhasilan yang diharapkan di setiap sel tabel:

Di mana f 0- jumlah keberhasilan atau kegagalan yang diamati dalam sel tertentu dari tabel kontingensi, fe
Uji χ 2 -statistik didekati dengan distribusi χ 2 - dengan satu derajat kebebasan.
Atau kegagalan di setiap sel tabel kontingensi tanda, perlu dipahami artinya. Jika hipotesis nol benar, yaitu. tingkat keberhasilan dalam dua populasi adalah sama, bagian sampel yang dihitung untuk masing-masing dari dua kelompok mungkin berbeda satu sama lain hanya karena alasan acak, dan kedua bagian tersebut merupakan perkiraan parameter umum populasi R. Dalam situasi ini, statistik yang menggabungkan kedua bagian dalam satu estimasi keseluruhan (rata-rata) dari parameter R , mewakili tingkat keberhasilan total dalam kelompok gabungan (yaitu sama dengan jumlah total keberhasilan dibagi dengan ukuran sampel total). Tambahannya, 1 – , mewakili tingkat kegagalan total dalam kelompok gabungan. Menggunakan notasi, artinya dijelaskan dalam tabel pada Gambar. 1. Anda dapat menurunkan rumus (2) untuk menghitung parameter :

Di mana - bagian rata-rata dari fitur tersebut.
Untuk menghitung jumlah keberhasilan yang diharapkan Fe(yaitu isi baris pertama dari tabel kontingensi fitur), ukuran sampel perlu dikalikan dengan parameter . Untuk menghitung jumlah kegagalan yang diharapkan fe(yaitu isi baris kedua dari tabel kontingensi fitur), ukuran sampel perlu dikalikan dengan parameter 1 – .
Statistik uji yang dihitung dengan rumus (1) didekati dengan distribusi χ 2 dengan satu derajat kebebasan. Untuk tingkat signifikansi tertentu α, hipotesis nol ditolak jika statistik χ 2 yang dihitung lebih besar dari χ U 2 , nilai kritis atas distribusi χ 2 dengan satu derajat kebebasan. Jadi aturan keputusannya terlihat seperti ini: hipotesis H 0 ditolak jika χ 2 > χ U 2 , sebaliknya hipotesis H 0 tidak menyimpang (Gbr. 3).

Beras. 3. Area kritis χ 2 -kriteria untuk membandingkan saham pada tingkat signifikansi α
Jika hipotesis nol benar, statistik χ 2 yang dihitung mendekati nol karena kuadrat dari perbedaan antara yang diamati F 0 dan diharapkan Fe nilai dalam setiap sel sangat kecil. Di sisi lain, jika hipotesis nol H 0 salah dan ada perbedaan yang signifikan antara tingkat keberhasilan dalam populasi, statistik χ 2 yang dihitung harus besar. Hal ini disebabkan oleh perbedaan antara jumlah keberhasilan atau kegagalan yang diamati dan yang diharapkan di setiap sel, yang meningkat saat mengkuadratkan. Namun, kontribusi dari perbedaan antara nilai yang diharapkan dan yang diamati terhadap keseluruhan χ 2 -statistik mungkin tidak sama. Perbedaan sebenarnya yang sama antara f 0 Dan fe mungkin memiliki efek yang lebih besar pada χ 2 -statistik jika sel berisi hasil dari sejumlah kecil pengamatan daripada perbedaan yang sesuai dengan jumlah pengamatan yang lebih besar.
Untuk mengilustrasikan uji χ 2 untuk menguji hipotesis kesetaraan dua saham, mari kita kembali ke skenario yang dijelaskan sebelumnya, yang hasilnya ditunjukkan pada Gambar. 2. Hipotesis nol (H 0: p 1 = p 2) menyatakan bahwa ketika membandingkan kualitas layanan di dua hotel, proporsi tamu yang berencana kembali tahun depan hampir sama. Untuk mengevaluasi parameter R, mewakili proporsi tamu yang berencana untuk kembali ke hotel, jika hipotesis nol benar, maka digunakan nilai , yang dihitung dengan rumus

Pangsa tamu yang tidak puas dengan layanan = 1 - 0,6483 = 0,3517. Mengalikan kedua proporsi ini dengan jumlah tamu yang disurvei di hotel Beachcomber memberikan perkiraan jumlah tamu yang berencana untuk kembali musim depan, serta jumlah wisatawan yang tidak lagi menginap di hotel ini. Demikian pula, bagian tamu yang diharapkan di hotel Windsurfer dihitung:
Ya - Beachcomber:
= 0,6483, N 1
= 227, oleh karena itu, fe = 147,16.
Ya - Peselancar Angin:
= 0,6483, N 2
= 262, oleh karena itu, fe = 169,84.
Tidak - Beachcomber: 1 -
= 0,3517, N 1
= 227, oleh karena itu, fe = 79,84.
Tidak - Selancar Angin: 1 -
= 0,3517, N 2
= 262, oleh karena itu, fe = 92,16.
Perhitungan disajikan dalam gambar. 4.

Beras. 4. χ 2 -statistik untuk hotel: (a) data awal; (b) tabel faktor 2x2 untuk membandingkan yang diamati ( F 0 ) dan diharapkan ( Fe) jumlah tamu yang puas dan tidak puas dengan layanan; (c) perhitungan statistik χ 2 ketika membandingkan proporsi tamu yang puas dengan pelayanan; (d) perhitungan nilai kritis uji χ2 statistik
Untuk menghitung nilai kritis dari uji χ 2 statistik, kami menggunakan fungsi Excel=XI2.INV(). Jika tingkat signifikansi α = 0,05 (probabilitas yang disubstitusi ke dalam fungsi HI2.OBR adalah 1 – α), dan distribusi χ 2 untuk tabel faktorial 2×2 memiliki satu derajat kebebasan, nilai kritis statistik χ 2 adalah 3.841. Karena nilai yang dihitung dari χ 2 -statistik, sama dengan 9,053 (Gbr. 4c), melebihi angka 3,841, hipotesis nol ditolak (Gbr. 5).

Beras. 5. Penentuan nilai kritis uji χ 2 -statistika dengan satu derajat kebebasan pada taraf signifikansi α = 0,05
Kemungkinan R bahwa hipotesis nol benar ketika χ 2 -statistik adalah 9,053 (dan satu derajat kebebasan) dihitung di Excel menggunakan fungsi =1 - CHI2.DIST(9,053;1;TRUE) = 0,0026. R-nilai sama dengan 0,0026 adalah probabilitas bahwa perbedaan antara bagian sampel tamu yang puas dengan layanan di hotel Beachcomber dan Windsurfer sama dengan atau lebih besar dari 0,718 - 0,588 = 0,13, jika ternyata bagian mereka di kedua populasi adalah sama. Dengan demikian, ada alasan bagus untuk menyatakan bahwa ada perbedaan yang signifikan secara statistik dalam layanan tamu antara kedua hotel tersebut. Penelitian menunjukkan bahwa jumlah tamu yang puas dengan pelayanan di Beachcomber lebih banyak dibandingkan dengan jumlah tamu yang berencana menginap di Windsurfer lagi.
Memeriksa asumsi tentang tabel faktor 2×2. Untuk mendapatkan hasil yang akurat berdasarkan data yang diberikan dalam tabel 2x2, diperlukan jumlah keberhasilan atau kegagalan melebihi angka 5. Jika kondisi ini tidak terpenuhi, maka kriteria Fisher.
Saat membandingkan persentase pelanggan yang puas dengan kualitas layanan di dua hotel, kriteria Z dan χ 2 menghasilkan hasil yang sama. Ini bisa dijelaskan dengan adanya koneksi dekat antara distribusi normal standar dan distribusi χ 2 dengan satu derajat kebebasan. Dalam hal ini, χ 2 -statistik selalu merupakan kuadrat dari statistik-Z. Misalnya, saat menilai kepuasan tamu, kami menemukan itu Z-statistik adalah +3,01, dan χ 2 -statistik adalah 9,05. Mengabaikan kesalahan pembulatan, mudah untuk memverifikasi bahwa nilai kedua adalah kuadrat dari yang pertama (yaitu 3,01 2 = 9,05). Selain itu, dengan membandingkan nilai kritis kedua statistik pada tingkat signifikansi α = 0,05, dapat diketahui bahwa nilai χ 1 2 sama dengan 3,841 adalah kuadrat dari nilai kritis atas statistik Z, sama dengan +1,96 (yaitu χ 1 2 = Z 2). Lebih-lebih lagi, R- nilai kedua kriteria sama.
Dengan demikian, dapat dikatakan bahwa ketika menguji hipotesis nol dan alternatif H 0: p 1 \u003d p 2; H 1: p 1 ≠ p 2 kriteria Z dan χ 2 ekuivalen. Namun, jika diperlukan tidak hanya untuk mendeteksi perbedaan, tetapi juga untuk menentukan proporsi mana yang lebih besar (p 1 > p 2), sebaiknya terapkan uji-Z dengan satu wilayah kritis yang dibatasi oleh ekor distribusi normal standar. Berikut akan dijelaskan penerapan uji χ 2 untuk membandingkan proporsi suatu fitur dalam beberapa kelompok. Perlu dicatat bahwa Z-test tidak dapat diterapkan dalam situasi ini.
Penerapan kriteria χ 2 - untuk menguji hipotesis persamaan beberapa saham
Uji chi-kuadrat dapat diperluas ke kasus yang lebih umum dan digunakan untuk menguji hipotesis bahwa beberapa bagian dari suatu sifat adalah sama. Mari kita tunjukkan jumlah populasi independen yang dianalisis dengan surat itu Dengan. Sekarang tabel kontingensi fitur terdiri dari dua baris dan Dengan kolom. Untuk menguji hipotesis nol dan alternatif H 0: p 1 \u003d p 2 = … = hal 2, Jam 1: Tidak semua RJ sama satu sama lain (J = 1, 2, …, C), uji χ 2 -statistik digunakan:
Di mana f 0- jumlah keberhasilan atau kegagalan yang diamati dalam sel tertentu dari tabel faktor 2* Dengan, Fe- jumlah keberhasilan atau kegagalan teoritis, atau diharapkan, dalam sel tertentu dari tabel kontingensi, asalkan hipotesis nol benar.
Untuk menghitung jumlah keberhasilan atau kegagalan yang diharapkan di setiap sel tabel kontingensi, Anda perlu memperhatikan hal-hal berikut. Jika hipotesis nol benar dan tingkat keberhasilan di semua populasi sama, bagian sampel yang sesuai dapat berbeda satu sama lain hanya karena alasan acak, karena semua bagian adalah perkiraan bagian fitur. R pada populasi umum. Dalam situasi ini, statistik yang menggabungkan semua bagian dalam satu estimasi parameter keseluruhan (atau rata-rata). R, berisi lebih banyak informasi daripada keduanya satu per satu. Statistik ini, dilambangkan dengan simbol , mewakili keseluruhan (atau rata-rata) proporsi keberhasilan dalam sampel yang dikumpulkan.
Perhitungan rata-rata bagian:

Untuk menghitung jumlah keberhasilan yang diharapkan fe di baris pertama tabel kontingensi fitur, volume setiap sampel perlu dikalikan dengan parameter . Untuk menghitung jumlah kegagalan yang diharapkan fe di baris kedua tabel kontingensi fitur, volume setiap sampel perlu dikalikan dengan parameter 1 – . Statistik uji yang dihitung dengan rumus (1) didekati dengan distribusi χ 2. Jumlah derajat kebebasan distribusi ini diberikan oleh kuantitas (r - 1)(C – 1) , Di mana R- jumlah baris dalam tabel faktor, Dengan- jumlah kolom dalam tabel. Untuk tabel faktor 2*s jumlah derajat kebebasan adalah (2 - 1)(s - 1) = s - 1. Untuk tingkat signifikansi tertentu α, hipotesis nol ditolak jika statistik χ 2 yang dihitung lebih besar dari nilai kritis atas χ U 2 yang melekat pada distribusi χ 2 dengan s - 1 derajat kebebasan. Jadi aturan keputusannya terlihat seperti ini: hipotesis H 0 ditolak jika χ 2 > χ U 2 (Gbr. 6), jika tidak hipotesis ditolak.

Beras. 6. Area kritis χ 2 -kriteria perbandingan dengan proporsi pada tingkat signifikansi α
Memeriksa asumsi tentang tabel faktor 2*c. Untuk mendapatkan hasil yang akurat berdasarkan data yang diberikan pada tabel faktor 2* Dengan, jumlah keberhasilan atau kegagalan harus cukup besar. Beberapa ahli statistik percaya bahwa kriteria memberikan hasil yang akurat jika frekuensi yang diharapkan lebih besar dari 0,5. Peneliti yang lebih konservatif mensyaratkan bahwa tidak lebih dari 20% sel tabel kontingensi mengandung nilai yang diharapkan kurang dari 5, dan tidak ada sel yang mengandung nilai yang diharapkan kurang dari satu. Kondisi terakhir bagi kami tampaknya merupakan kompromi yang masuk akal di antara ekstrem-ekstrem ini. Untuk memenuhi kondisi ini, kategori yang mengandung nilai ekspektasi kecil harus digabungkan menjadi satu. Setelah itu, kriteria menjadi lebih tepat. Jika karena beberapa alasan tidak memungkinkan untuk menggabungkan beberapa kategori, prosedur alternatif harus diterapkan.
Untuk mengilustrasikan uji χ2 untuk menguji hipotesis pembagian yang sama dalam beberapa kelompok, mari kita kembali ke skenario yang dijelaskan di awal bab ini. Pertimbangkan survei serupa yang melibatkan tamu dari tiga hotel TC Resort Resources (Gambar 7a).

Beras. 7. Tabel faktor 2×3 untuk membandingkan jumlah tamu yang puas dan tidak puas dengan layanan: (a) jumlah keberhasilan atau kegagalan yang diamati - f 0; (b) jumlah keberhasilan atau kegagalan yang diharapkan - Fe; (c) perhitungan χ 2 -statistik saat membandingkan bagian tamu yang puas dengan layanan tersebut
Hipotesis nol menyatakan bahwa proporsi pelanggan yang berencana untuk kembali tahun depan hampir sama di semua hotel. Untuk mengevaluasi parameter R, yang merupakan proporsi tamu yang berencana untuk kembali ke hotel, nilainya digunakan R = X /N= 513 / 700 = 0,733. Porsi tamu yang tidak puas dengan layanan ini adalah 1 - 0,733 = 0,267. Mengalikan tiga bagian dengan jumlah tamu yang disurvei di setiap hotel, kami mendapatkan jumlah tamu yang diharapkan yang berencana untuk kembali musim depan, serta jumlah pelanggan yang tidak lagi menginap di hotel ini (Gbr. 7b).
Untuk menguji hipotesis nol dan alternatif, uji χ 2 -statistik digunakan, dihitung menggunakan nilai yang diharapkan dan diamati sesuai dengan rumus (1) (Gbr. 7c).
Nilai kritis dari uji χ 2 -statistika ditentukan dengan rumus =XI2.OBR(). Karena tiga hotel ikut serta dalam survei, χ 2 -statistik memiliki (2 – 1)(3 – 1) = 2 derajat kebebasan. Pada tingkat signifikansi α = 0,05, nilai kritis statistik χ 2 adalah 5,991 (Gbr. 7d). Karena χ 2 -statistik yang dihitung, sama dengan 40,236, melebihi nilai kritis, hipotesis nol ditolak (Gbr. 8). Di sisi lain, probabilitas R bahwa hipotesis nol benar untuk χ 2 -statistik sama dengan 40,236 (dan dua derajat kebebasan) dihitung di Excel menggunakan fungsi =1-XI2.DIST() = 0,000 (Gbr. 7d). R-nilai sama dengan 0,000 dan lebih kecil dari taraf signifikansi α = 0,05. Oleh karena itu, hipotesis nol ditolak.

Beras. Gambar 8. Daerah penerimaan dan penolakan hipotesis persamaan tiga saham pada tingkat signifikansi 0,05 dan dua derajat kebebasan
Menolak hipotesis nol saat membandingkan proporsi yang ditunjukkan pada tabel faktor 2* Dengan, kami hanya dapat menyatakan bahwa persentase tamu yang puas dengan layanan di ketiga hotel tersebut tidak sesuai. Untuk mengetahui saham mana yang berbeda dari yang lain, perlu diterapkan metode lain, misalnya prosedur Marasquilo.
prosedur Marasquilo memungkinkan Anda membandingkan semua grup secara berpasangan. Pada tahap pertama prosedur, perbedaan p s j – p s j ’ dihitung (di mana J ≠ J’ ) di antara s(s – 1)/2 pasangan saham. Rentang kritis yang sesuai dihitung dengan rumus:

Pada tingkat signifikansi keseluruhan α, nilainya adalah akar kuadrat dari nilai kritis atas dari distribusi chi-kuadrat yang memiliki s - 1 derajat kebebasan. Untuk setiap pasang bagian sampel, perlu untuk menghitung rentang kritis yang terpisah. Pada tahap terakhir, masing-masing s(s – 1)/2 sepasang ketukan dibandingkan dengan rentang kritis yang sesuai. Saham-saham yang membentuk suatu pasangan tertentu dianggap berbeda nyata secara statistik jika selisih absolut antara saham-saham sampel |p s j – p s j | melebihi batas kritis.
Mari kita ilustrasikan prosedur Marasquilo pada contoh survei tamu di tiga hotel (Gbr. 9a). Dengan menerapkan uji chi-square, kami menemukan bahwa terdapat perbedaan yang signifikan secara statistik antara proporsi tamu dari berbagai hotel yang akan kembali tahun depan. Karena survei melibatkan tiga tamu hotel, perlu dilakukan 3(3 - 1)/2 = 3 perbandingan berpasangan dan menghitung tiga rentang kritis. Pertama, mari kita hitung tiga bagian sampel (Gbr. 9b). Dengan tingkat signifikansi umum 0,05, nilai kritis atas uji χ 2 -statistik untuk distribusi "chi-square", yang memiliki (c - 1) = 2 derajat kebebasan, ditentukan dengan rumus = XI2.OBR (0,95; 2) = 5,991. Jadi, = 2,448 (Gbr. 9c). Selanjutnya, kami menghitung tiga pasang perbedaan absolut dan rentang kritis yang sesuai. Jika perbedaan absolut lebih besar dari kisaran kritisnya, maka bagian yang sesuai dianggap berbeda secara signifikan (Gbr. 9d).

Beras. Gambar 9. Hasil prosedur Marasquilo untuk menguji hipotesis bagian yang sama dari tamu yang puas dari tiga hotel: (a) data survei; (b) sampel saham; (c) nilai kritis atas statistik uji χ 2 untuk distribusi chi-kuadrat; (d) tiga pasang perbedaan mutlak dan rentang kritis yang sesuai
Seperti yang Anda lihat, pada tingkat signifikansi 0,05, tingkat kepuasan tamu hotel Palm Royal (p s2 = 0,858) lebih tinggi daripada tamu Golden Palm (p s1 = 0,593) dan Palm Princess hotel (p s3 = 0,738). Selain itu, tingkat kepuasan tamu Palm Princess Hotel lebih tinggi dibandingkan dengan tamu Golden Palm Hotel. Hasil ini harus mendorong manajemen untuk menganalisis alasan perbedaan ini dan mencoba menentukan mengapa tingkat kepuasan tamu Golden Palm jauh lebih rendah daripada hotel lain.
Bahan dari buku Levin et al.Statistik untuk manajer digunakan. - M.: Williams, 2004. - hal. 708–730
Uji chi-square Pearson adalah metode non-parametrik yang memungkinkan Anda untuk menilai signifikansi perbedaan antara jumlah hasil aktual (terungkap sebagai hasil penelitian) atau karakteristik kualitatif sampel yang termasuk dalam setiap kategori dan jumlah teoretis yang dapat diharapkan dalam kelompok belajar jika hipotesis nol benar. Dalam istilah yang lebih sederhana, metode ini memungkinkan Anda mengevaluasi signifikansi statistik dari perbedaan antara dua atau lebih indikator relatif(frekuensi, saham).
1. Sejarah perkembangan kriteria χ 2
Tes chi-kuadrat untuk analisis tabel kontingensi dikembangkan dan diusulkan pada tahun 1900 oleh seorang ahli matematika, ahli statistik, ahli biologi dan filsuf Inggris, pendiri statistik matematika dan salah satu pendiri biometrik. Karl Pearson(1857-1936).
2. Untuk apa kriteria χ 2 Pearson digunakan?
Uji chi-square dapat diterapkan dalam analisis tabel kontingensi berisi informasi tentang frekuensi hasil tergantung pada adanya faktor risiko. Misalnya, tabel kontingensi empat bidang sebagai berikut:
| Keluaran adalah (1) | Tidak ada jalan keluar (0) | Total | |
| Ada faktor risiko (1) | A | B | A+B |
| Tidak ada faktor risiko (0) | C | D | C+D |
| Total | A+C | B+D | A+B+C+D |
Bagaimana cara mengisi tabel kontingensi seperti itu? Mari kita pertimbangkan contoh kecil.
Sebuah studi sedang dilakukan tentang efek merokok pada risiko pengembangan hipertensi arteri. Untuk ini, dua kelompok subjek dipilih - yang pertama termasuk 70 orang yang merokok setidaknya 1 bungkus rokok setiap hari, yang kedua - 80 bukan perokok pada usia yang sama. Pada kelompok pertama, 40 orang mengalami tekanan darah tinggi. Yang kedua - hipertensi arteri diamati pada 32 orang. Dengan demikian, tekanan darah normal pada kelompok perokok adalah pada 30 orang (70 - 40 = 30) dan pada kelompok bukan perokok - pada 48 (80 - 32 = 48).
Kami mengisi tabel kontingensi empat bidang dengan data awal:
Dalam tabel kontingensi yang dihasilkan, setiap baris sesuai dengan kelompok mata pelajaran tertentu. Kolom - menunjukkan jumlah orang dengan hipertensi arteri atau dengan tekanan darah normal.
Tantangan bagi peneliti adalah: adakah perbedaan yang signifikan secara statistik antara frekuensi penderita tekanan darah antara perokok dan bukan perokok? Anda dapat menjawab pertanyaan ini dengan menghitung uji chi-kuadrat Pearson dan membandingkan nilai yang dihasilkan dengan nilai kritis.
3. Kondisi dan batasan penggunaan uji chi-square Pearson
- Indikator yang sebanding harus diukur dalam skala nominal(misalnya, jenis kelamin pasien - laki-laki atau perempuan) atau di urut(misalnya, derajat hipertensi arteri, mengambil nilai dari 0 sampai 3).
- Metode ini memungkinkan analisis tidak hanya dari tabel empat bidang, ketika faktor dan hasilnya adalah variabel biner, yaitu, mereka hanya memiliki dua nilai yang mungkin (misalnya, pria atau wanita, ada tidaknya penyakit tertentu dalam sejarah ...). Uji chi-square Pearson juga dapat digunakan dalam kasus analisis tabel multibidang, ketika faktor dan (atau) hasil mengambil tiga nilai atau lebih.
- Kelompok yang dicocokkan harus independen, yaitu uji chi-kuadrat tidak boleh digunakan saat membandingkan pengamatan sebelum-sesudah. Tes McNemar(ketika membandingkan dua populasi terkait) atau dihitung Uji-Q Cochran(dalam hal membandingkan tiga kelompok atau lebih).
- Saat menganalisis tabel empat bidang nilai-nilai yang diharapkan di setiap sel harus minimal 10. Jika di setidaknya satu sel fenomena yang diharapkan mengambil nilai dari 5 hingga 9, uji chi-kuadrat harus dihitung dengan koreksi Yates. Jika dalam setidaknya satu sel fenomena yang diharapkan kurang dari 5, maka analisis harus digunakan Tes eksak Fisher.
- Dalam kasus analisis tabel multi-bidang, jumlah pengamatan yang diharapkan tidak boleh mengambil nilai kurang dari 5 di lebih dari 20% sel.
4. Bagaimana cara menghitung uji chi-square Pearson?
Untuk menghitung uji chi-kuadrat, Anda harus:

Algoritma ini berlaku untuk tabel empat bidang dan multi bidang.
5. Bagaimana menginterpretasikan nilai uji chi-square Pearson?
Jika nilai yang diperoleh dari kriteria χ 2 lebih besar dari kriteria kritis, kami menyimpulkan bahwa ada hubungan statistik antara faktor risiko yang diteliti dan hasil pada tingkat signifikansi yang sesuai.
6. Contoh penghitungan uji chi-square Pearson
Mari kita tentukan signifikansi statistik dari pengaruh faktor merokok terhadap kejadian hipertensi arteri menurut tabel di atas:
- Kami menghitung nilai yang diharapkan untuk setiap sel:
- Temukan nilai uji chi-square Pearson:
χ 2 \u003d (40-33.6) 2 / 33.6 + (30-36.4) 2 / 36.4 + (32-38.4) 2 / 38.4 + (48-41.6) 2 / 41.6 \u003d 4.396.
- Jumlah derajat kebebasan f = (2-1)*(2-1) = 1. Kami menemukan nilai kritis uji chi-square Pearson dari tabel, yang pada tingkat signifikansi p = 0,05 dan jumlah derajat kebebasan 1, adalah 3,841.
- Kami membandingkan nilai yang diperoleh dari uji chi-square dengan yang kritis: 4,396 > 3,841, oleh karena itu, ketergantungan kejadian hipertensi arteri pada adanya merokok secara statistik signifikan. Tingkat signifikansi hubungan ini sesuai dengan p<0.05.
Pertimbangkan aplikasi diMSUNGGULUji chi-square Pearson untuk menguji hipotesis sederhana.
Setelah menerima data percobaan (yaitu ketika ada beberapa Sampel) biasanya hukum distribusi dipilih yang paling menggambarkan variabel acak disajikan oleh ini contoh. Memeriksa seberapa baik data eksperimen dijelaskan oleh hukum distribusi teoretis yang dipilih dilakukan dengan menggunakan kriteria persetujuan. hipotesis nol, biasanya ada hipotesis bahwa distribusi variabel acak sama dengan beberapa hukum teoretis.
Mari kita lihat dulu aplikasinya Uji kesesuaian Pearson X 2 (chi-kuadrat) dalam kaitannya dengan hipotesis sederhana (parameter distribusi teoretis diasumsikan diketahui). Kemudian - , ketika hanya bentuk distribusi yang ditentukan, dan parameter distribusi ini serta nilainya statistik X 2 diperkirakan/dihitung berdasarkan hal yang sama sampel.
Catatan: Dalam literatur berbahasa Inggris, prosedur aplikasi Tes kebaikan Pearson X 2 memiliki nama Uji kecocokan chi-kuadrat.
Ingat prosedur untuk menguji hipotesis:
- berdasarkan sampel nilai dihitung statistik, yang sesuai dengan jenis hipotesis yang diuji. Misalnya untuk digunakan T-statistik(jika tidak diketahui);
- tunduk pada kebenaran hipotesis nol, distribusi ini statistik diketahui dan dapat digunakan untuk menghitung probabilitas (misalnya, untuk T- statistik Ini );
- dihitung berdasarkan sampel arti statistik dibandingkan dengan nilai kritis untuk nilai yang diberikan ();
- hipotesis nol ditolak jika nilainya statistik lebih besar dari kritis (atau jika probabilitas mendapatkan nilai ini statistik() lebih sedikit tingkat signifikansi, yang merupakan pendekatan ekuivalen).
Ayo habiskan pengujian hipotesis untuk distribusi yang berbeda.
Kasus diskrit
Misalkan dua orang sedang bermain dadu. Setiap pemain memiliki set dadu mereka sendiri. Pemain bergiliran melempar 3 dadu sekaligus. Setiap putaran dimenangkan oleh orang yang mendapatkan angka enam lebih banyak sekaligus. Hasilnya dicatat. Salah satu pemain setelah 100 ronde curiga tulang lawannya tidak simetris, karena. dia sering menang (sering melempar enam). Dia memutuskan untuk menganalisis seberapa besar kemungkinan hasil lawan sebanyak itu.
Catatan: Karena 3 dadu, maka Anda dapat melempar 0 sekaligus; 1; 2 atau 3 angka enam, mis. variabel acak dapat mengambil 4 nilai.
Dari teori probabilitas, kita tahu bahwa jika kubus-kubus itu simetris, maka probabilitas angka enam akan mengikuti. Oleh karena itu, setelah 100 putaran, frekuensi enam dapat dihitung menggunakan rumus
=BINOM.DIST(A7,3,1/6,FALSE)*100
Rumus mengasumsikan bahwa sel A7 berisi jumlah enam yang dijatuhkan dalam satu putaran.
Catatan: Perhitungan diberikan di contoh file pada sheet Discrete.
Untuk perbandingan diamati(Diamati) dan frekuensi teoretis(Diharapkan) nyaman digunakan.

Dengan penyimpangan yang signifikan dari frekuensi yang diamati dari distribusi teoretis, hipotesis nol tentang distribusi variabel acak menurut hukum teoritis, harus ditolak. Artinya, jika dadu lawan tidak simetris, maka frekuensi yang diamati akan "berbeda secara signifikan" dari distribusi binomial.
Dalam kasus kami, pada pandangan pertama, frekuensinya cukup dekat dan sulit untuk menarik kesimpulan yang tidak ambigu tanpa perhitungan. Berlaku Tes kesesuaian Pearson X 2, sehingga bukan pernyataan subyektif "berbeda nyata", yang dapat dibuat berdasarkan perbandingan histogram, gunakan pernyataan yang benar secara matematis.
Mari kita gunakan fakta bahwa hukum bilangan besar frekuensi teramati (observed) dengan bertambahnya volume sampel n cenderung ke probabilitas yang sesuai dengan hukum teoretis (dalam kasus kami, hukum binomial). Dalam kasus kami, ukuran sampel n adalah 100.
Mari perkenalkan tes statistik, yang kami nyatakan dengan X 2:

di mana O l adalah frekuensi kejadian yang diamati bahwa variabel acak telah mengambil nilai tertentu yang dapat diterima, E l adalah frekuensi teoretis yang sesuai (Diharapkan). L adalah jumlah nilai yang dapat diambil oleh variabel acak (dalam kasus kami sama dengan 4).
Seperti yang bisa dilihat dari rumusnya, ini statistik adalah ukuran kedekatan frekuensi yang diamati dengan yang teoretis, yaitu itu dapat digunakan untuk memperkirakan "jarak" antara frekuensi ini. Jika jumlah "jarak" ini "terlalu besar", maka frekuensi ini "berbeda secara substansial". Jelas bahwa jika kubus kita simetris (mis. berlaku hukum binomial), maka kemungkinan jumlah "jarak" akan "terlalu besar" akan kecil. Untuk menghitung probabilitas ini, kita perlu mengetahui distribusinya statistik X 2 ( statistik X 2 dihitung berdasarkan acak sampel, jadi itu adalah variabel acak dan, oleh karena itu, memiliki sendiri distribusi kemungkinan).
Dari analog multidimensi teorema integral Moivre-Laplace diketahui bahwa untuk n->∞ variabel acak kita X 2 asimtotik dengan L - 1 derajat kebebasan.
Jadi jika dihitung nilainya statistik X 2 (jumlah "jarak" antar frekuensi) akan lebih dari nilai batas tertentu, maka kita akan memiliki alasan untuk menolak hipotesis nol. Seperti dalam pemeriksaan hipotesis parametrik, nilai batas ditetapkan melalui tingkat signifikansi. Jika probabilitas bahwa statistik X 2 akan mengambil nilai kurang dari atau sama dengan yang dihitung ( P-arti) akan lebih sedikit tingkat signifikansi, Itu hipotesis nol dapat ditolak.
Dalam kasus kita, nilai statistiknya adalah 22,757. Probabilitas statistik X 2 akan mengambil nilai lebih besar atau sama dengan 22,757 sangat kecil (0,000045) dan dapat dihitung dengan menggunakan rumus
=XI2.DIST.PX(22.757;4-1) atau
=XI2.TEST(Diamati; Diharapkan)
Catatan: Fungsi CH2.TEST() dirancang khusus untuk menguji hubungan antara dua variabel kategori (lihat ).
Probabilitas 0,000045 jauh lebih kecil dari biasanya tingkat signifikansi 0,05. Jadi, pemain memiliki banyak alasan untuk mencurigai ketidakjujuran lawannya ( hipotesis nol tentang kejujurannya ditolak).

Saat diterapkan kriteria X 2 perawatan harus diambil untuk memastikan bahwa volume sampel n cukup besar, jika tidak perkiraan distribusi akan menjadi tidak valid statistik X 2. Biasanya dianggap bahwa untuk ini cukup bahwa frekuensi yang diamati (Diamati) lebih besar dari 5. Jika tidak demikian, maka frekuensi rendah digabungkan menjadi satu atau digabungkan ke frekuensi lain, dan nilai gabungan diberikan total probabilitas dan, karenanya, jumlah derajat kebebasan berkurang X 2 -distribusi.
Untuk meningkatkan kualitas aplikasi kriteria X 2(), perlu untuk mengurangi interval partisi (meningkatkan L dan, karenanya, menambah jumlahnya derajat kebebasan), namun, hal ini dicegah dengan pembatasan jumlah pengamatan yang termasuk dalam setiap interval (d.b.>5).
kasus terus menerus
Uji kebaikan Pearson X 2 dapat diterapkan dengan cara yang sama dalam kasus .
Pertimbangkan beberapa contoh, terdiri dari 200 nilai. Hipotesis nol menyatakan bahwa Sampel terbuat dari .
Catatan: Variabel acak di file sampel pada lembar Berkelanjutan dihasilkan dengan menggunakan rumus =NORM.ST.INV(RAND()). Oleh karena itu, nilai-nilai baru sampel dihasilkan setiap kali sheet dihitung ulang.
Apakah kumpulan data yang tersedia memadai dapat dinilai secara visual.

Seperti yang Anda lihat dari diagram, nilai sampel cukup pas di sepanjang garis lurus. Namun, seperti untuk pengujian hipotesis berlaku Uji kesesuaian Pearson X 2 .
Untuk melakukan ini, kami membagi rentang variasi variabel acak menjadi interval dengan langkah 0,5. Mari kita hitung frekuensi teramati dan teoretis. Kami menghitung frekuensi yang diamati menggunakan fungsi FREQUENCY(), dan yang teoretis - menggunakan fungsi NORM.ST.DIST().
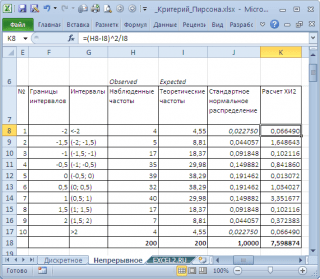
Catatan: Adapun kasus diskrit, perlu untuk memastikan bahwa Sampel cukup besar, dan lebih dari 5 nilai jatuh ke dalam interval.
Hitung statistik X 2 dan bandingkan dengan nilai kritis untuk yang diberikan tingkat signifikansi(0,05). Karena kami membagi rentang variasi variabel acak menjadi 10 interval, maka jumlah derajat kebebasan adalah 9. Nilai kritis dapat dihitung dengan rumus
\u003d XI2.INV.RH (0,05; 9) atau
\u003d XI2.OBR (1-0,05; 9)
Bagan di atas menunjukkan bahwa nilai statistik adalah 8,19, yang jauh lebih tinggi kritis – hipotesis nol tidak ditolak.
Di bawah ini yang mana Sampel diasumsikan nilai tidak mungkin, dan atas dasar kriteria Persetujuan Pearson X 2 hipotesis nol ditolak (terlepas dari kenyataan bahwa nilai acak dihasilkan menggunakan rumus =NORM.ST.INV(RAND()) menyediakan contoh dari distribusi normal baku).

Hipotesis nol ditolak, meskipun secara visual data cukup mendekati garis lurus.
Sebagai contoh, mari kita ambil juga contoh dari U(-3; 3). Dalam hal ini, bahkan dari grafik terlihat jelas hipotesis nol harus ditolak.

Kriteria Persetujuan Pearson X 2 juga menegaskan hal itu hipotesis nol harus ditolak.
Misalkan H 0 adalah F(x) = F 0 (x); hipotesis alternatif Н 1: F(x) ¹ F 0 (x). Dalam uji kecocokan Pearson, variabel acak c 2 diambil sebagai statistik, yang nilai empirisnya ditentukan oleh rumus
di mana k adalah jumlah interval di mana nilai SW X yang dipelajari dibagi; m i – frekuensi interval i; pi adalah probabilitas SS X jatuh ke interval ke-i, dihitung untuk hukum distribusi teoretis.
Sebagai n ® ¥, SW cenderung berdistribusi c 2 s l= k – r – 1 derajat kebebasan, dimana k adalah jumlah interval, r adalah jumlah parameter distribusi teoritis yang dihitung dari data eksperimen.
Persyaratan bahwa n ® ¥ sangat penting. Dalam praktiknya, volume n ³ 50 dan jumlah pengamatan dalam setiap interval m i dianggap paling sedikit 5. Jika dalam setiap interval m i< 5, то имеет смысл объединить соседние интервалы.
Mari kita gambarkan algoritma untuk menerapkan kriteria c 2 .
1. Nilai ditemukan
2. Untuk level a yang dipilih menurut Lampiran VI, carilah nilai , dimana l= k - r - 1.
3. Jika £, maka hipotesis H 0 diterima, yaitu kita dapat berasumsi bahwa hukum distribusi teoretis dan empiris bertepatan; Jika
> , maka hipotesis H 0 ditolak.
CONTOH 29.2. Saat menabur benih rami, indikator penting adalah kedalaman penempatan benih. 100 pengukuran dilakukan untuk mengevaluasi penyemaian. Hasil pengukuran ditunjukkan pada Tabel 29.3.
Tabel 29.3.
Dengan menggunakan kriteria c 2, uji hipotesis H 0 tentang distribusi normal SS X - kedalaman penempatan benih pada taraf signifikansi a = 0,01.
Larutan. Mari kita cari dan S B menurut data sampel
Karena dalam interval ekstrim nilai m i< 5, объединим их.
Tabel 29.4.
1. Mari kita cari probabilitas pi mengenai SV X dalam interval ke-i menurut rumus
di mana kami menemukan nilai menggunakan Tabel II lampiran.
Penyelidikan: .
Mari kita hitung nilainya:
2. l\u003d k - r - 1 \u003d 5 - 2 - 1 \u003d 2. Menurut tabel II, kami menemukan \u003d 9.21.
3. Sejak< , то гипотезу Н 0 о нормальном распределении СВ Х отвергать нет оснований.
§ 30. Menguji hipotesis tentang homogenitas sampel (kriteria non parametrik).
Biarkan ada dua sampel independen yang diambil dari populasi yang hukum distribusinya tidak diketahui. Hipotesis yang diuji H 0: F 1 (x) = F 2 (x), di mana F 1 (x) dan F 2 (x) adalah fungsi distribusi yang tidak diketahui. Hipotesis alternatif H 1: F 1 (x) ¹ F 2 (x).
Kriteria Kolmogorov-Smirnov. Kriteria ini diterapkan jika dapat diasumsikan bahwa fungsi F 1 (x) dan F 2 (x) adalah kontinu.
Nilai
dimana n 1 , n 2 masing-masing adalah volume sampel pertama dan kedua, F 1,E (x), F 2,E (x) adalah fungsi distribusi empiris dari sampel pertama dan kedua.
Jika hipotesis H 0 valid untuk sampel yang cukup besar (n 1 ³ 50, n 2 ³ 50), distribusinya konvergen dengan distribusi Kolmogorov (tabel VII lampiran). Untuk sampel kecil, tabel khusus digunakan untuk mencari Dcr.
Hipotesis H 0 diuji sebagai berikut. Jika
> D cr, maka hipotesis ditolak, selain itu diterima.
CONTOH 30.1. Untuk mempelajari pengaruh obat tertentu terhadap pertumbuhan anak babi, dilakukan percobaan yang hasilnya ditunjukkan pada tabel 30.1.
Tabel 30.1.
Pada saat yang sama, anak babi pada kelompok kontrol diberi makan tanpa menggunakan obat (tabel 30.2).
Tabel 30.2.
Diperlukan pada tingkat signifikansi a = 0,05 untuk menguji hipotesis H 0 bahwa kedua sampel dijelaskan oleh fungsi distribusi yang sama, yaitu obat tersebut tidak berpengaruh signifikan terhadap pertumbuhan anak babi.
Larutan. Kami akan memasukkan data perhitungan dalam tabel, dengan mempertimbangkan itu
n 1 \u003d 100, n 2 \u003d 200.
Tabel 30.3.
Menggunakan tabel VII lampiran, kami temukan
D cr \u003d D 1 - a \u003d D 0,95 "K 0,95 \u003d 1,36.
Sejak D cr< , то гипотезу Н 0 следует принять, т.е. препарат не оказывает существенного влияния на рост поросят.
Jika sampelnya kecil, akan lebih mudah digunakan Uji Wilcoxon-Whitney.
Mari kita merumuskan aturan penerapannya (n 1 £ 25, n 2 £ 25). Untuk menguji hipotesis H 0 : F 1 (x) = F 2 (x) dengan hipotesis alternatif H 1 : F 1 (x) ¹ F 2 (x) adalah sebagai berikut :
1. Gabungkan dua sampel menjadi satu dan atur opsi dalam urutan menaik, hitung W - jumlah dari jumlah opsi sampel yang lebih kecil.
2. Temukan dari tabel VIII Lampiran w lower.cr = w( , n 1 , n 2) dan w upper.cr =
\u003d (n 1 + n 2 + 1) n 1 - w lebih rendah cr.
Jika w n.cr< W < w в.кр, то нет оснований отвергнуть гипотезу, в противоположном случае гипотеза Н 0 отвергается.
Catatan 30.1. Jika ada opsi pencocokan di antara mereka, maka masing-masing diberi peringkat yang sama dengan rata-rata aritmatika dari nomor urut opsi pencocokan dalam deret umum, yang menggantikan nomor opsi pencocokan.
Catatan 30.2. Uji Wilcoxon-Whitney juga dapat digunakan untuk sampel besar. Dalam hal ini, perhitungan w n.cr dan w v.cr berubah (lihat).
CONTOH 30.2. Untuk memperkirakan upah (dalam c.u.), dua sampel n 1 = 8 dan n 2 = 9 dikumpulkan di dua perusahaan:
Perusahaan ke-I 330, 390, 400, 410, 420, 450, 460, 470
II perusahaan 340, 400, 410, 420, 430, 440, 460, 480, 490
Dengan menggunakan uji Wilcoxon-Whitney, uji hipotesis nol H 0 tentang gaji yang sama di dua perusahaan, terhadap hipotesis H 1: gaji berbeda (a = 0,05).
Larutan. Mari membentuk deret variasi umum
330 ; 340; 390 ; 400 ; 400; 410 ; 410; 420 ; 420; 430; 440; 450 ; 460 ; 460; 470 ; 480; 490
1 2 34,5 4,5 6,5 6,5 8,5 8,5 10 11 1213,5 13,5 15 16 17
Untuk menerapkan uji Wilcoxon-Whitney di atas, sampel pertama haruslah sampel dengan ukuran terkecil n 1 = 8.
Mari kita cari nilai W. Untuk melakukan ini, kita menggarisbawahi nomor seri varian sampel yang lebih kecil dan menemukan jumlahnya:
W = 1 + 3 + 4,5 + 6,5 + 8,5 + 12 + 13,5 + 15 = 64.
Temukan nilai w lebih rendah.cr = w(0,025; 8; 9) = 51.
Carilah nilai w top.cr = (n 1 + n 2 + 1) n 1 - w n.cr = (8 + 9 + 1) × 8 - 51 = 93.
Karena relasi w n.cr< W < w в.кр (51 < 64 < 93), то нет оснований отвергнуть гипотезу Н 0 , т.е. оплата труда на I-м и II-м предприятиях различается незначительно.
ODA. Frekuensi empiris sebenarnya frekuensi yang diamati.
VERIFIKASI HIPOTESIS TENTANG DISTRIBUSI POPULASI UMUM. KRITERIA PEARSON
Seperti disebutkan sebelumnya, asumsi tentang jenis distribusi dapat dikemukakan berdasarkan premis teoretis. Namun, tidak peduli seberapa baik hukum distribusi teoretis dipilih, perbedaan tidak dapat dihindari antara distribusi empiris dan teoretis. Pertanyaan yang muncul secara alami: apakah perbedaan ini hanya disebabkan oleh keadaan acak yang terkait dengan sejumlah pengamatan yang terbatas, atau apakah perbedaan tersebut signifikan dan terkait dengan fakta bahwa hukum distribusi teoretis tidak berhasil dipilih. Kriteria kesepakatan berfungsi untuk menjawab pertanyaan ini, yaitu
ODA. Kriteria konkordansi disebut kriteria untuk menguji hipotesis hukum yang diusulkan dari distribusi yang tidak diketahui.
Untuk setiap kriteria, mis. distribusi yang sesuai, tabel biasanya dikompilasi, menurut yang mereka temukan k kr (lihat lampiran). Setelah titik kritis ditemukan, nilai kriteria yang diamati dihitung dari data sampel KE obs. Jika KE ob > k kr, maka hipotesis nol ditolak, jika sebaliknya, maka diterima.
Mari kita jelaskan penerapan kriteria Pearson untuk menguji hipotesis distribusi normal populasi umum. Kriteria Pearson menjawab pertanyaan apakah perbedaan antara frekuensi empiris dan teoritis adalah kebetulan?
Kriteria Pearson, seperti kriteria lainnya, tidak membuktikan validitas hipotesis, tetapi hanya menetapkan, pada tingkat signifikansi yang diterima, persetujuan atau ketidaksetujuannya dengan data pengamatan.
Jadi, misalkan distribusi empiris diperoleh dari sampel berukuran n. Pada tingkat signifikansi a, diperlukan pengujian hipotesis nol: populasi berdistribusi normal.
Sebagai kriteria untuk menguji hipotesis nol, diambil variabel acak c 2 =, dimana frekuensi empirisnya; - frekuensi teoretis.
SW ini memiliki c 2 - distribusi dengan k - derajat kebebasan. Jumlah derajat kebebasan ditemukan dengan persamaan k=m –r -1, m adalah jumlah interval sampling parsial; r adalah jumlah parameter distribusi. Untuk distribusi normal r=2 (a dan s), maka k=m –3.
Untuk menguji hipotesis nol pada tingkat signifikansi tertentu: populasi terdistribusi secara normal, diperlukan:
1. Hitung rata-rata sampel dan simpangan baku sampel.
2. Hitung frekuensi teoritis,
di mana n adalah ukuran sampel; h - langkah (perbedaan antara dua opsi yang berdekatan); ; nilai fungsi melihat aplikasi.
3. Bandingkan frekuensi empiris dan teoretis menggunakan uji Pearson. Untuk ini:
a) menemukan nilai yang diamati dari kriteria ;
b) menurut tabel titik distribusi kritis c 2 , menurut tingkat signifikansi yang diberikan a dan jumlah derajat kebebasan k, temukan titik kritis .
Jika< - нет оснований отвергнуть нулевую гипотезу. Если >- Hipotesis nol ditolak.
Komentar. Beberapa frekuensi (<5) следует объединить; в этом случае и соответствующие им теоретические частоты также надо сложить. Если производилось объединение частот, то при определении числа степеней свободы следует в качестве m принять число групп выборки, оставшихся после объединения частот.